
|

|
Same network generates the image at both
30x30 and 1080x1080 pixel resolution.
GitHub
Introduction
In the previous post, we constructed a generative model that can draw MNIST digits at a very high image resolution, using a latent space vector representation of images. The generator network uses the CPPN model to produce images of any specified resolution. Now using the same model from last time, we will try to apply it naively to train on the CIFAR-10 dataset.
There is still a lot of work to be done, because the current model is nowhere able to fit a large space of possible colour images, but I thought it would be interesting to see what we can generate out of the model as is. Currently, the model tends to draw a few states of images only, so the encoding function of the VAE will not work well, because there is too much variety in the set of training images for this model to handle.
Exploring different generative architectures
The architecture of the CPPN limits the space of what types of images are possible to be drawn by the network. Different architectures correspond to different types of images being generated, despite training on similar data sets.
So in addition to modifying the output regression from the MNIST model to have three outputs rather than one to model colour, we also played around with a variety of different architectures for the generator network. Also, using the model as it is to train on the entire CIFAR-10 data would not really work well, because CIFAR-10 contains such a wide range of different images containing different things, from airplanes to boats to birds to frogs. Below is an example of an interesting image coming out of CPPN after training on the entire set with our model.

Abstract CIFAR-10?
We notice the image is not as random as the images generated from a CPPN network purely with random weights, but still the image doesn’t resemble much unless you really read into the abstract interpretations of such an image (you can become an art critic!). What we can try to do is to train the model with just one class within CIFAR-10 and see if we have more luck. Or at least try to get the model to capture some typical structures, such as the colouring or types of shapes we see in images of a certain class.
In our experiments, we play around with different architectures in the generator class in model.py. For example, we can set every layer in the generator to be tanh:
Pure tanh generative network
1
2
3
4
5
6
H = tf.nn.tanh(U)
for i in range(1, self.net_depth_g):
H = tf.nn.tanh(fully_connected(H, n_network, self.model_name+'_g_tanh_'+str(i)))
output = tf.nn.sigmoid(fully_connected(H, self.c_dim, self.model_name+'_g_'+str(self.net_depth_g)))
The picture below was generated from 8 layers of pure tanh layers, and trained on the frog class of CIFAR-10. We can tell as the lines and surface are very curved and smooth. However, this model was prone to instabilities, because as 10 layers of a tanh network wouldn’t deal with gradients that well in the GAN training.

Amphibian Origins (2016)
To add a bit of structure and rigidity in the generator, I tried to make the first layer a rectifier relu layer, and released this model to train on the truck class of CIFAR-10, to see what sort of image we get.
relu activation before the tanh generators
1
2
3
4
5
6
H = tf.nn.relu(U)
for i in range(1, self.net_depth_g):
H = tf.nn.tanh(fully_connected(H, n_network, self.model_name+'_g_tanh_'+str(i)))
output = tf.nn.sigmoid(fully_connected(H, self.c_dim, self.model_name+'_g_'+str(self.net_depth_g)))
Below is a cool sample of the image generated from this type of network. We can see some structure in the image, and the rigid lines are due to the relu layer at the beginning.

Ground Terrain (2016)
I like this structural effect from the relu layers, but at the same time I don’t want to sacrifice the smoothness offered from the sigmoid type activations, so I played around with the architecture a bit, and decided on a repeating relu and tanh combination to train on the set of frog data in CIFAR-10.
Repeating relu and tanh layers
1
2
3
4
5
6
7
H = tf.nn.relu(U)
for i in range(1, self.net_depth_g):
H = tf.nn.tanh(fully_connected(H, n_network, self.model_name+'_g_tanh_'+str(i)))
H = tf.nn.relu(fully_connected(H, n_network, self.model_name+'_g_relu_'+str(i)))
output = tf.nn.sigmoid(fully_connected(H, self.c_dim, self.model_name+'_g_'+str(self.net_depth_g)))
Now let’s see how this architecture models a subclass of CIFAR-10.
CIFAR-10 Frogs

|

|
A note on how we did our training. Images in CIFAR-10 database come as 32x32 pixel images. We subsample a slightly smaller image inside each training image, so that our training image is actually 30x30 pixels. In addition, we randomly flip the images horizontally during training. These tricks can increase the usefulness of the small amount of data available in each class (6000 pictures of frogs in the train + test set).
Samples from CIFAR-10’s Frog Class:

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
After training the modified CPPN-GAN-VAE model on the set of frog data, we can sample a few images from the model to see how they look like:
Samples of CPPN Frogs:

|

|
|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
|

|
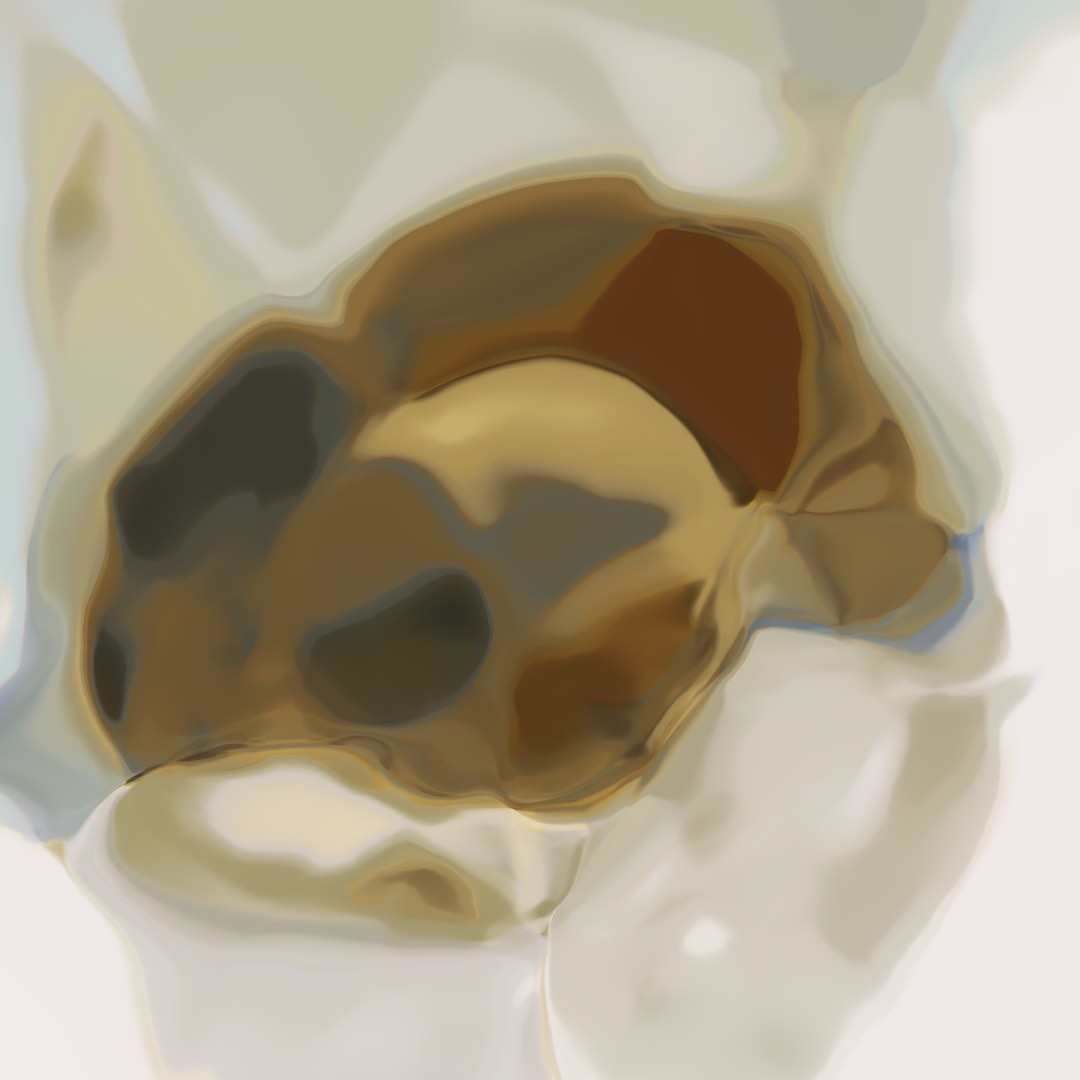
We see the samples above sort of resembles some amphibious like creature, and there’s some shades of colours and patterns that are similar to parts of the sample set, but obviously we have a long way to go. The richness of the colour types and many different styles of frogs have been left out. However, with this set, we can try to upsample the images to 1080x1080 to see what these pixellated samples look in higher resolution.
CPPN Frogs at High Resolution:

|

|
|

|

|

|

|

|

|

|

|
|

|

|

|

|

|

|
|

|
I think at the higher resolution, these images are more interesting than the images generated from the generator with purely random weights. At least it seems to be trying to express some sort of theme or mood to the audience.
The space of 'frog' images quite limited in the model.
CIFAR-10 Trucks

|

|
I’ve also experimented with training the model on the truck class of the CIFAR-10 data. In addition, I have also tried to remove the radius input for CPPN, so the only inputs will be the latent vector, and x and y coordinates, ). I found that sometimes the radius constrains the type of image space we can generate, although it gives us the curve effects for free.
Below is a sample of generated images from this model after training on the truck class. The CPPN’s space of colours after training on the truck class are a bit different from the colours after training on the frog class. Maybe there are more orange/red/brighter colours in the training data for trucks.
CPPN CIFAR Truck Samples at 30x30 and 1080x1080:

|

|

|

|

|

|

|

|

|

|
I’ve also attempted to use the VAE encoder to encode original samples into the limited latent space to see what representations the CPPN can generate. Obviously the space is way too limited, but it is interesting to see certain features getting captured by the network.
| Sample | Encoded | 1080x1080 |

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|

|
As we can see, the model is quite limited in the few variety of images it can generate, and it tries to choose the closest state for each sample fed in the autoencoder’s input.
Conclusions
There is still a lot of work to be done before making this CPPN type of network to be able to generate rich images, compared to simple MNIST digits. I think there is some value to getting them to work to generate rich colour images, because this type of network allows us to upscale to very large resolutions. I’ve thought of a few things that might be worthwhile to try in the future:
-
Modify the VAE encoder network from a fully connected 2 layer softplus network into a deeper CNN that can identify better features from images in a spatial invariant way.
-
Train on a discrete cosine transformed version of the images, and have the network generate a DCT representation of new images to be inverted back to spatial domain.
-
Modify generator network to take advantage of residual / stochastic layer type of training. Getting a 10-plus layer network to learn is proving to be very challenging. Any attempt at dropout will also make the network generate very blurry images.
-
Replace fully-connected layers in the generator by sparsely connected layers, or CNN-type connections. Try to have a DCGAN type of architecture but the generator will have to function like a CPPN.
I’ve put the code for this demo here on GitHub, in case you want to play around with making CPPNs train on colour images. The code modifies the CPPN-GAN-VAE model previously used for generating high resolution MNIST images to train on the CIFAR-10 set. It’s a bit hacked together and I feel a bit shameful for releasing code of this quality, but I hope you will be able to have better success with this than me!
Please let me know if you can get it to do draw interesting things.