It has been around a year to eighteen months when I immersed myself into learning some fundamentals of modern machine learning techniques. I’ve thrown myself into the standard mooc courses, gone through more advanced materials on neural networks by Hinton, a legend in this field, and some courses on computational neuroscience.
One of the best tutorials on the web is the Stanfard Deep Learning tutorial. The pre-requisite is probably the standard mooc course, and from there, the tutorial takes you to more advanced concepts such as stochastic gradient descent methods, sparse auto-encoders, convolutional neural networks, natural language processing, which represents the state of the art currently in how large computer farms help us analyse and understand natural information in text, images, videos, sound and speech.
The exercise on the sparse auto-encoder was one of my favourite. Where I thought forward-feeding neural-networks were just a really complicated non-linear function trained to map many-to-few, the auto-encoder takes the output of the forward-feed network and feeds it back by comparing to the original image, hence converting it into a recursive structure with powerful properties in a well defined framework that is easy to train. This reminds me of the old days of linear signals and systems analysis and control systems theory.
An auto-encoder:
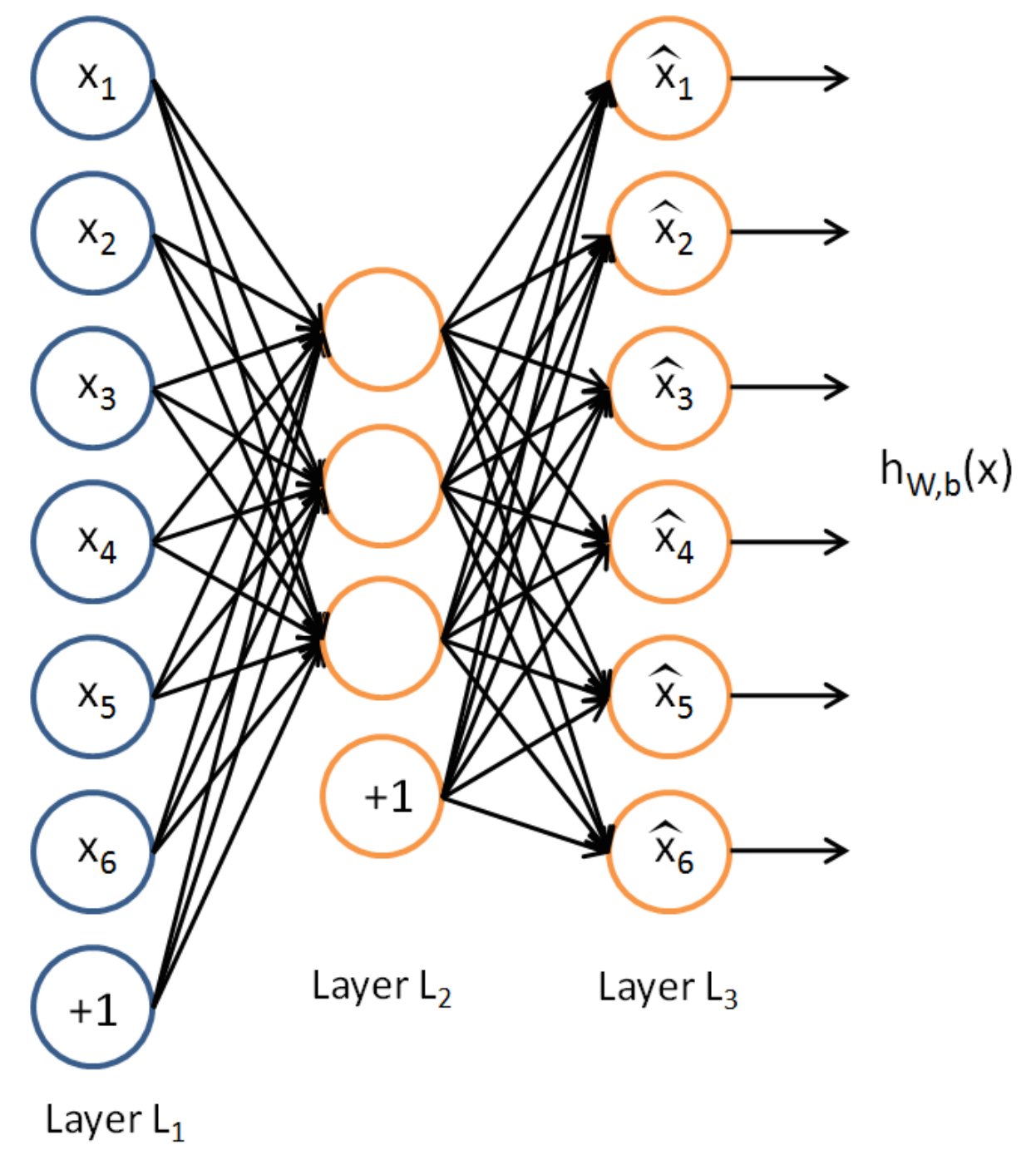
By studying the weights of the auto-encoder neural network, one can get a glimpse of the essense of the data. For example, by training a sparse auto-encoder to recognise handwritten digits, one can examine the weights of the network, and see what the statistical best filters look like:

In the example above, every hand-written sample will be represented by a combination of at most a dozen of the filters above, and the rest will be ignored. From those dozen filter labels, a simple algorithm will be able to predict with high accuracy what digit was written. That’s essentially the basics of digit recognition to get up to ~ 97% accuracy. The last 3% will involve convolutional neural network concepts, although those concepts are more useful in image and object recognition.
What is more interesting though, is to train randomly sampled, say 8×8 images extracted at random from the digits data, rather than the full images, to see if there is something significant in handwriting. If we randomly sample pieces of sub 8×8-sized images from our full collection, and run the sparse auto-encoder training, we will get the set of weights below:

This tells us that the natural handwritten images are decomposed of a set of edges with various rotation angles. What is more interesting is if we do this exercise on natural photographs, we will see a similar set of basis vectors that can be used to compress images (or understand them using convolutional neural networks). Studies in neuroscience also show that certain neurons in our brain fire up when they see edges at certain angles, in a sense, applying a sparse-encoder like process to decode what the brain thinks it is seeing from the eyes.
It goes without saying that this stuff can go quite deep, into a never ending quest to understand how our brains work.