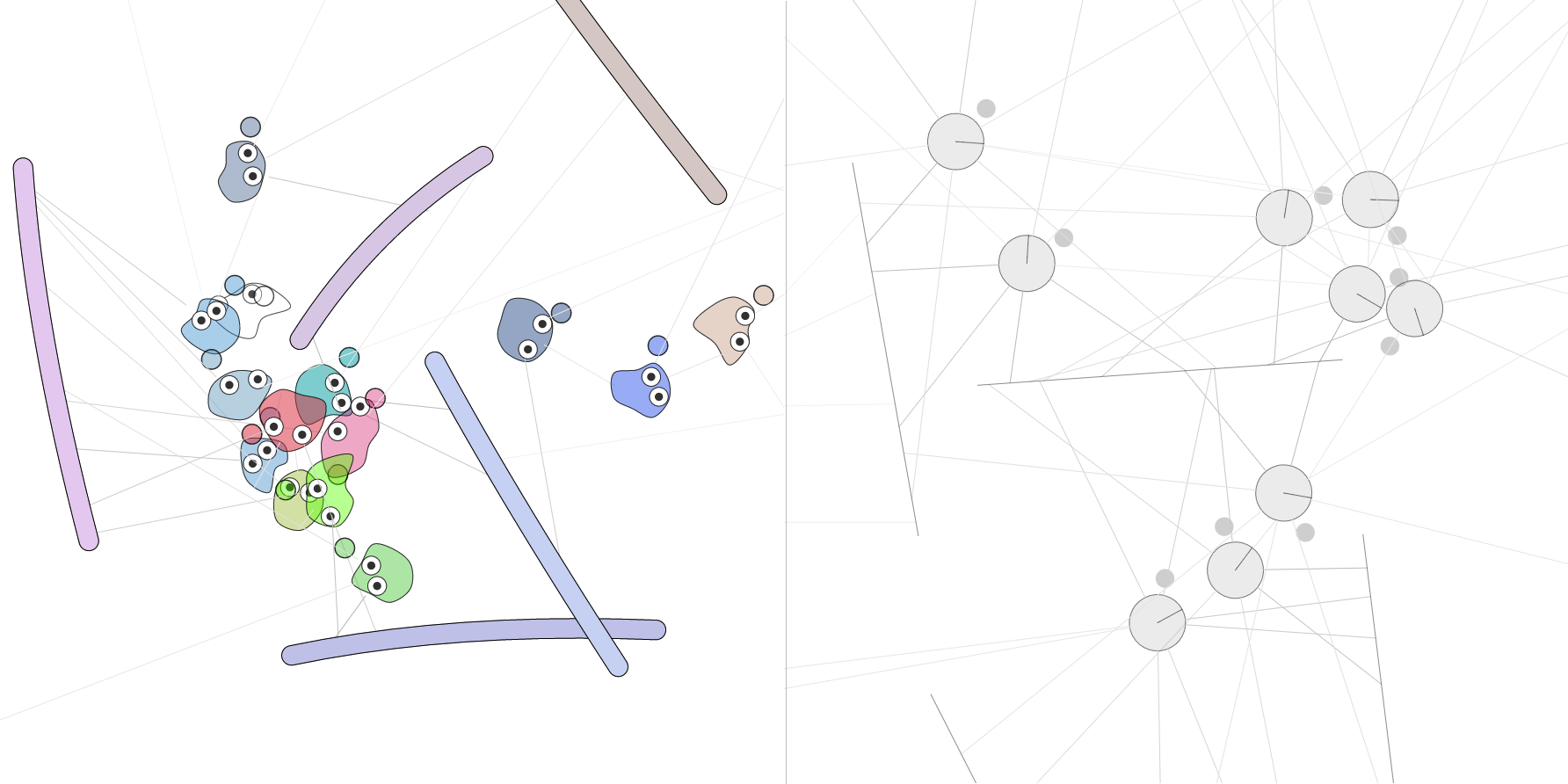
Agents with neural net brains evolved to survive – try javascript demo here
Update: This post has been translated to Japanese and Chinese.
Recently I came across a video of a simulation that demonstrates the use of evolutionary techniques to train agents to avoid moving obstacles. The methodology used seems to employ a variation of the NEAT algorithm used to evolve the topology of neural networks so that it can perform certain tasks correctly. It was written to be used in the Unity 5 game engine to be incorporated to general game AIs which interested me.
The results are really cool and the dynamics seemed quite elegant, so I wanted to try to implement a similar demo in javascript that can run inside a browser session. After playing around with a basic implementation, I found out that for obstacle avoiding problems, it turns out that a very simple neural network can be used effectively, and that even a fully connected neural network can be overkill. I also realised in the end that that even a simple perceptron-like network works quite well, and that hidden units may not add much advantage in the previously mentioned obstacle avoiding demo.
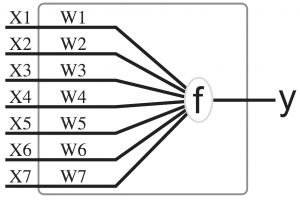
simple perceptron diagram (wikipedia)
The task became too easy, and can be overkill to use the NEAT algorithm, since the agent is free to move in any direction instantaneously when an obstacle is detected and the agent does not get interfered with the actions of other agents. Using a simple perceptron-like network (which is just a single-neuron network), the agent can easily perform the task of avoiding walls effectively.
Making life hard for our agents, because life is hard.
I decided to make things a little bit interesting by adding a few conditions to make the task harder.
- Movement is constrained to a strict version of Reynolds Steering, outlined in this paper for creating lifelike simulation behaviours, as opposed to being able to swift towards any direction freely.
- The agent can decide to either steer left, or steer right. It cannot move straight. Like a car without any power steering, it must also move forward towards steering direction as it steers. I wanted to see if the agent can develop a steering pattern behaviour to move quickly in the direction straight ahead by quickly switching between steering left and right. This makes things difficult, as you can imaging driving a car where you are either constantly steering fully left or fully right, just to try to travel in a straight line ahead.
- Agents collide with each other, so they may need to develop a strategy to either avoid other agents, or the evil side of me hope they run each other into the planks, if the fitness function was set this way.
I find that with these extra constraints, a simple single-neuron decision maker was not sufficient for the agents to be even semi decent. I still think the task shouldn’t require advanced methodologies such as ESP or NEAT, and I still wanted to be able to use the off-the-shelf convnet.js library for the neural network, so I opted for the same super simple neural network architecture used for the neural slime volleyball project. Below is my first attempt at it:
Each agent’s brain is comprised of ten neurons, and each neuron is connected to all the inputs, and to all other the neurons as well, perhaps like a slice of a small area inside a real brain. Below is a schematic of the brain:

basic diagram of the neural network – each brain has 269 weights
This network architecture is called the fully connected recurrent network. Each agent has a bunch of perception inputs, that feed into the recurrent network. Two of the ten neurons control the agent’s motion, and the rest are “hidden neuron units” for computation and thought. All neuron output signals are fed back into the input layer, so that every neuron is fully connected with the other neurons, with a time lag of one frame (~ 1/30s)
The first neuron in the output layer is used to control whether the agent will steer left, or right, depending on the sign of the output. As we use the hyperbolic tangent function for neuron activation, the neurons will have output values between -1 and 1, so making such a binary left/right decision becomes natural. The second neuron controls whether the agent moves or stays idle, depending also on the sign of the output.
Training the network
A population of 100 agents initialised with random weights are used in the training, and they will get to run around in the simulation until they all get killed by a plank. It sucks to have to have everyone die at the end of the simulation, but in the end we all have to die …
Afterwards all the agents die in one single simulation, we keep the genes of the 30 agents that survive the longest during the simulation for the next generation, and discard the other 70 agents. The genes of the top 30, which are just vectors of neural connection weights and biases will be cross-mutated to be passed on to 70 newly born agents in the next generation. This process (explained in the Reproduction section below) is continued until the best agent becomes proficient at avoiding planks and survives for more than five minutes of simulated time.
Below is a demo of the evolution simulation in action, with the first generation being a completely random network (I scaled this demo to 50 agents rather than 100 so most computers even smartphones can run it). At the beginning, most agents don’t attempt to survive (or simply give up!), but maybe one or two has some clue what’s going on and do a bit better, so they get to move on to the next generation and reproduce. After a few generations, you can see incremental abilities of the population, as they all finally start to avoid the moving planks. I’m surprised that they already get quite good after only 30 generations. If you are interested, please see the training demo to see how they evolve from not knowing at all how to survive at the beginning. Notice that the results are updated every ten generations rather than every generation. This is because I want to evolve them as fast as possible, rather than limit the evolution at 30 frames per second, and run the simulations as fast as your computer will allow, and only run a simulation “for show” every ten generations so you can see and critique the progress in real time – the actual evolution is done behind the scenes between viewable simulations at light speed.
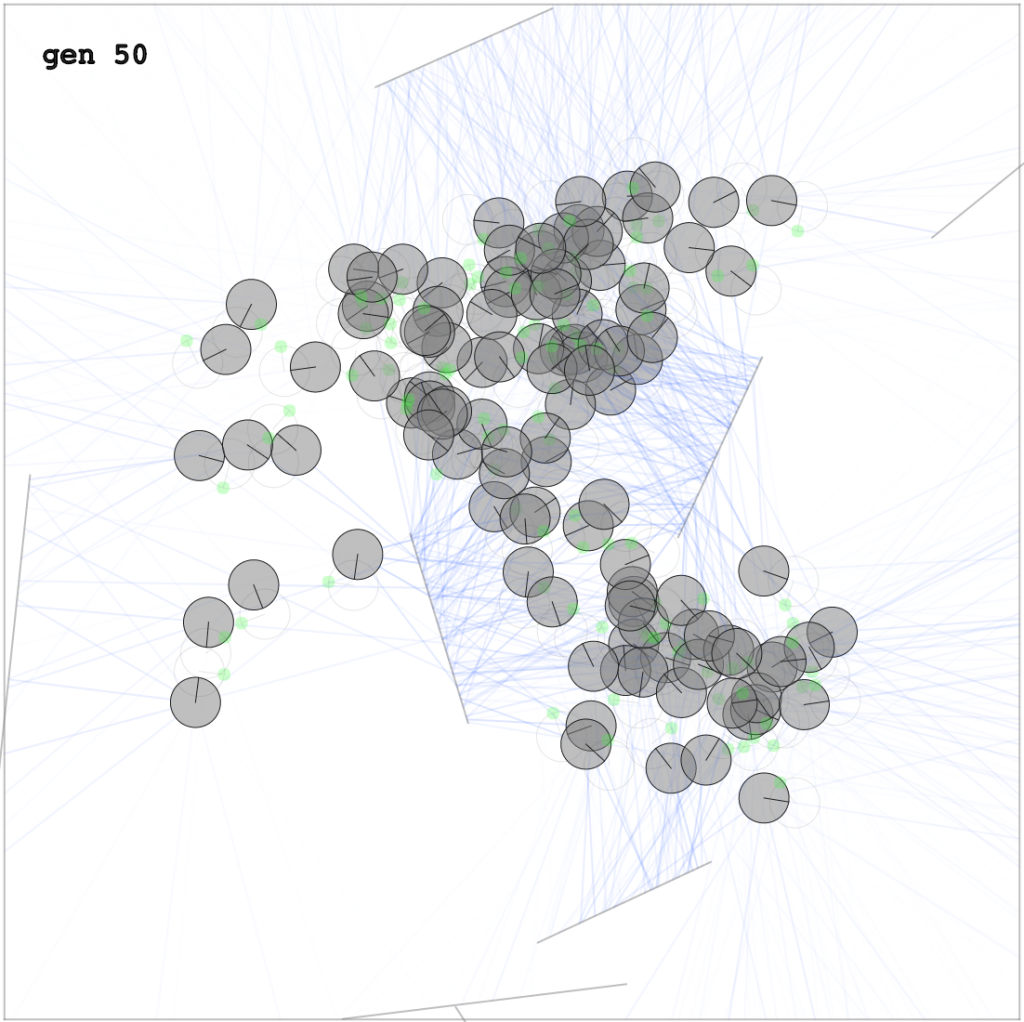
training from scratch – watch agents evolve from knowing nothing
The lines around the agent are its perception sensors, like retinal inputs, and they provide each agent with some perception capabilities of the world around them. Each line’s intensity becomes more solid as the agent perceives something that is closer to the agent, either a plank or another agent. Each agent has the ability to see in 8 directions around itself, up to a distance of 12 body-diameters away. I chose the signals in such a way that the closer a perceived object is, the closer the signal becomes one, and on the other extreme, if nothing is seen, the perceived signal becomes zero. If the agent sees something 6 diameters away, the signal will be 0.25 rather than 0.5, as I square the result to mimic light intensity models.
What if Wayne Gretzky got hit by a bus before having kids?
I also added a few tweaks to the training algorithm mentioned above.
One issue I had is some top performing agents will accidentally die off, even if they are awesome, just from sheer bad luck, due to the (deliberate) crowded nature of the agents in the simulation. A top wall-dodger agent from the last generation, may start off in the side of a crowd, and accidentally get pushed into a plank by a few other agents at the very beginning of the simulation, and hence not being able to pass its good genes to future generations.
I have thought about this problem for a while, and came up with the idea of incorporating a “hall of fame” section in the evolution algorithm, that will record the genes of agents that have achieved record scores from the very beginning of time. I have also modified my evolution library to incorporate this “hall of fame” feature, to keep the top 10 all-time-champions. For each simulation, the hall-of-famers are brought back to life to participate against the current generation. In that sense, each generation of agents will also have to compete against the greatest agents of all time. Imagine being able to train with the likes of Wayne Gretzkey, Doug Gilmour, and Tim Horton during every single season of Hockey!
This technique definitely boosted the results of evolution, as the best genes are forced kept in the population. It would be really scary if this sort of stuff happened in real life (although we may be there soon…). I thought I discovered a great novel technique in the world of evolutionary computing, and pushed the boundaries! However, after some digging, I read that hall-of-fame techniques have been already used in neuroevolution for playing Go. Well, too bad for me.
I wanted to see if agents will behave entirely differently if I evolved them again from scratch, and I spent a few days training different batches of agents, each for a thousand generations or so. It turns out that most agents end up with similar weight patterns. To see how different each agent’s brain looks like, I plotted out the ‘genetic code’ of the top performing agents, where I bundled batches of four weight values into a colour (RGBA – 4 channels) for effect.

Each row represents the weights of the most successfully evolved neural nets.
We can see that most of the top performers look similar, but with slight variations. This can, however, lead to problems as they are likely to be stuck at the same local optimum state. I can imagine some scenario where agents tend to develop the same suboptimal strategy of avoiding planks, and further progress cannot be made due to difficulty of the task. This is something where more advanced methods can tackle, but for now I’m fairly satisfied at the recurrent nets generated by simple conventional neuroevolution. I kept 23 top genes to use in the demo. The final simulation will initialise the brains by selecting random hall-of-famers from this trained batch.
Analysis of Results
After around a thousand generations of training, the agents became half decent at avoiding planks. Please see the final result in this demo. The agents are far from perfect, but they exhibit certain insect like behaviour which I find very interesting. I was surprised they can still perform the plank avoiding task while constrained to steering either totally to the left or the right. In the demo, each agent comes with a hand as well, which will indicate whether they are currently steering left or right. No hand means the agent is staying still. I was also happy to see that the agents can swift forward through empty spaces, when it wants to move forward in direction, as they developed some sort of pattern between switching steering left and right.
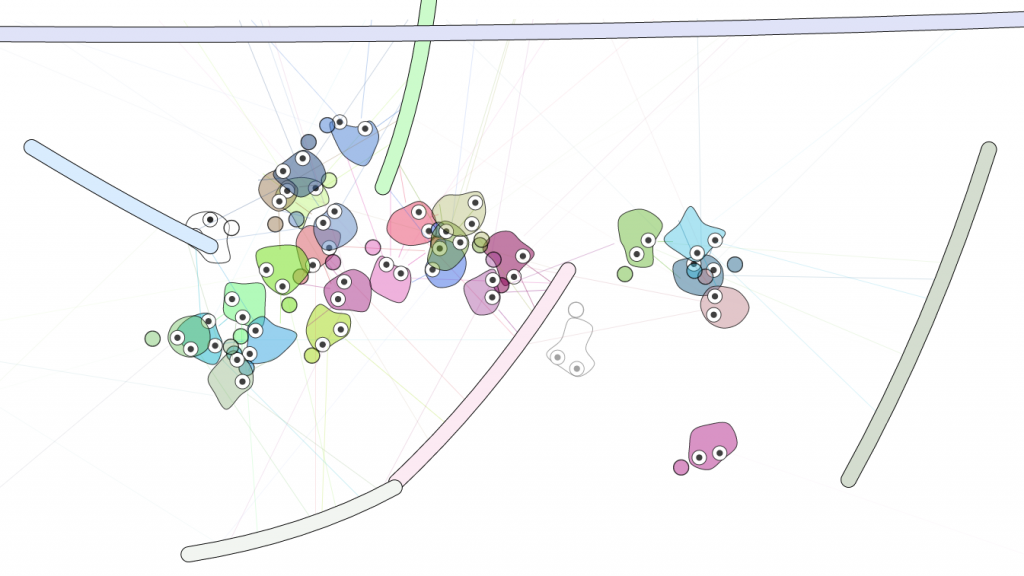
final simulation – otoro.net/planks
I also noticed that they tend to prefer to herd together with other agents and strive to be the centre of the crowd, and I’m not sure why. Perhaps it is because by being in the middle of a crowd, one can wait for the other agents to die off first to increase one’s survival chances. I’ve also thought about using relative life spans to the population average rather than absolute life spans for the fitness functions. Maybe with a more complicated network, that may entice behaviours for agents become evil and plot to kill off other agents.
Reproduction

offsprings carry genes of both parents
Rather than wait until all the agents die off, and creating new generations every time, to make the demo more interesting, I added the ability for agents to mate and make offsprings! This may also lead to an alternative intra-generation approach to evolve agents in the future, rather than fixing each generation’s population constant.
How this works is that for each agent, if they are able to survive for some random time (typically between 30 to 60 seconds), they have the capability to reproduce. If such an agent bumps into another such agent, then two offsprings are created. The offsprings are initially smaller and will grow to become adults after around 30-60s. The parent agent’s ‘urge clock’ resets to zero, and has to wait until 30-60s to reproduce again …
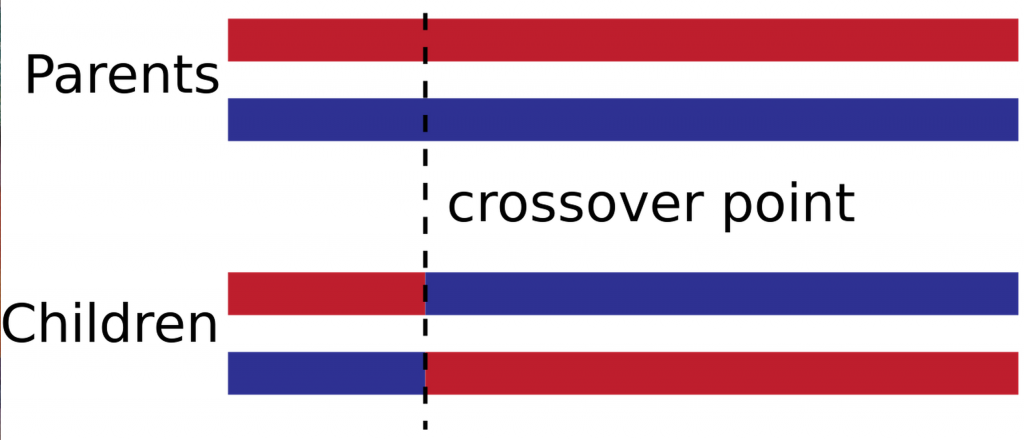
cross over algorithm (wikipedia)
The two offsprings will inherit the genes of both parents, via the super simple 1-point crossover method. So the first child will inherit the first chunk of neural net weights from the first parent, and the rest from the second parents, at a random cutoff point, as described by the diagram above. In addition, I added random mutations to each child, so they become slightly different and unique. This random mutation is also important to encourage innovation and adds something new to the population’s gene pool.
The theory is that the better agents have a better chance of surviving, hence have a higher chance to produce offsprings that carry their genes forward, and the weaker ones tend to die off before having kids, although sometimes the really good ones die too early due to bad luck. Well too bad for them – that’s life – life is not fair, and life is hard!
Interacting with Agents – Playing God
While using the demo, you can click or touch in empty parts of the screen to create new agents and place them into the simulation. The initial genes for a new agent is randomly chosen from the last few agents who managed to produce an offspring, or from the initial batch of hall-of-famers if no agents has reproduced yet.
If you click over a plank, the visual mode will jump to the next mode, for example, x-ray mode, border-less mode, pure creature mode with no hands, etc, for me to basically evaluate different designs and overall aesthetics. I think the x-ray mode with the perception looks cool, and works fast on slower machines.

x-ray-mode: behind the scenes
You can also exert a powerful force to push around the agents, by simply clicking on them. This simulates a temporary wind effect to push them away from the location of the mouse / touch point.
You can also create a plank, by dragging on the screen to draw a line. Depending on the direction drawn, the plank will either move in normal direction to the left or right of the plank. You can see how the agents react when you unleash some planks set out to destroy their civilisation! Please be nice with this new power, as I noticed that before this feature, users tend to cheer for the little guys, but after knowing about this feature, they set out to decimate every one of them!
Design and Development Considerations
I initially designed my creatures agents a few months ago while I was playing with the paper.js library. I really like that library as there are many awesome technical features to draw smooth lines in an object oriented way, from the way they designed the segment[] class in the library, and was thinking of using that to add more life-like features, such as fins or tadpole tails to the agents and create a swimming effect. However, performance is a big issue, as I also have to handle collision detection, not to mention running recurrent neural network brain computations of 100 agents in real time. In the end the p5 library is a very good compromise, and also have multiple curve functions. I was surprised how fast javascript is these days even as I made the creature rendering more complex by implementing the mean-reverting membrane of each creature to make them more lifelike.
I also used many tricks, such as precomputing sine and cosine tables for the purpose of rendering, to avoid using the actually Math.sin() and Math.cos() functions which may involved Taylor series expansion terms. Whenever I can, I compared distances by comparing the square of hypothenuse rather than the actual hypothenuse as it involves a Math.sqrt() computation which can also be slow, especially when it comes to N-body collision detection.
To make the planks more lifelike in the demo, I used bezier curves rather than drawing straight lines to for rendering the planks, and they would swing around with a Perlin noise function bundled with p5 library. This makes the planks swing around in an unnatural evil way, as if it was a haunted block of wood hungry for blood and revenge.
glass mode – no border lines
I also played around with the possibility of removing the borders of each agent, leaving them with a ‘glass’ effect, which looked cool, but in the end settled back on the version with the borders.
The design of creatures was indirectly influenced by my childhood memories of Ghibli anime, namely the black-dust creatures called Makkuro kurosuke (真っ黒黒助) from Totoro.

Makkuro Kurosuke (HPPD’s rendition)
As they have Japanese roots, I wanted to write the demo in Japanese, and also I want to learn more about rendering Japanese style text (right to left, top to bottom), and using different font styles, and perhaps modify the demo to suit an asian audience.
I don’t think w3 has formalised asian writing standards yet, and each browser has different keywords, which is a mess, but I found this cool css hack to allow me to try to use vertical style writing. I initially used the hack, but ended up following this beautiful vertical text example that webkit functions support, with the exception of firefox.
While I was browsing some design sites, I also found a font from mini-design.jp called ‘mini wakuwaku’ (even the name sounds fluffy and cute) that reminds me of kindergarten characters. The font doesn’t support kanji so the size is also very small for use as a web asset.
「mini-わくわく」kawaii fonts…
So I modified my demo a bit to convert into a Japanese version. Feel free to visit aomame.net to check it out. My attempt to post in Japanese:
壁避け『知能マメ』。遺伝的アルゴリズムを用いて進化した生物。 https://t.co/rMxGRNEgjq #機械学習 pic.twitter.com/jQo15Pukje
— hardmaru (@hardmaru) May 9, 2015
Citation
If you find this work useful, please cite it as:
@article{ha2015creatures,
title = "creatures avoiding planks",
author = "Ha, David",
journal = "blog.otoro.net",
year = "2015",
url = "https://blog.otoro.net/2015/05/07/creatures-avoiding-planks/"
}