We survey ideas from complex systems such as swarm intelligence, self-organization, and emergent behavior that are gaining traction in ML. (Figure: Emergence of encirclement tactics in MAgent.)
Introduction
Unless you’ve been living under a rock, you would’ve noticed that artificial neural networks are now used everywhere. They’re impacting our everyday lives, from performing predictive tasks such as recommendations, facial recognition and object classification, to generative tasks such as machine translation and image, sound, video generation. But with all of these advances, the impressive feats in deep learning required a substantial amount of sophisticated engineering effort.
|
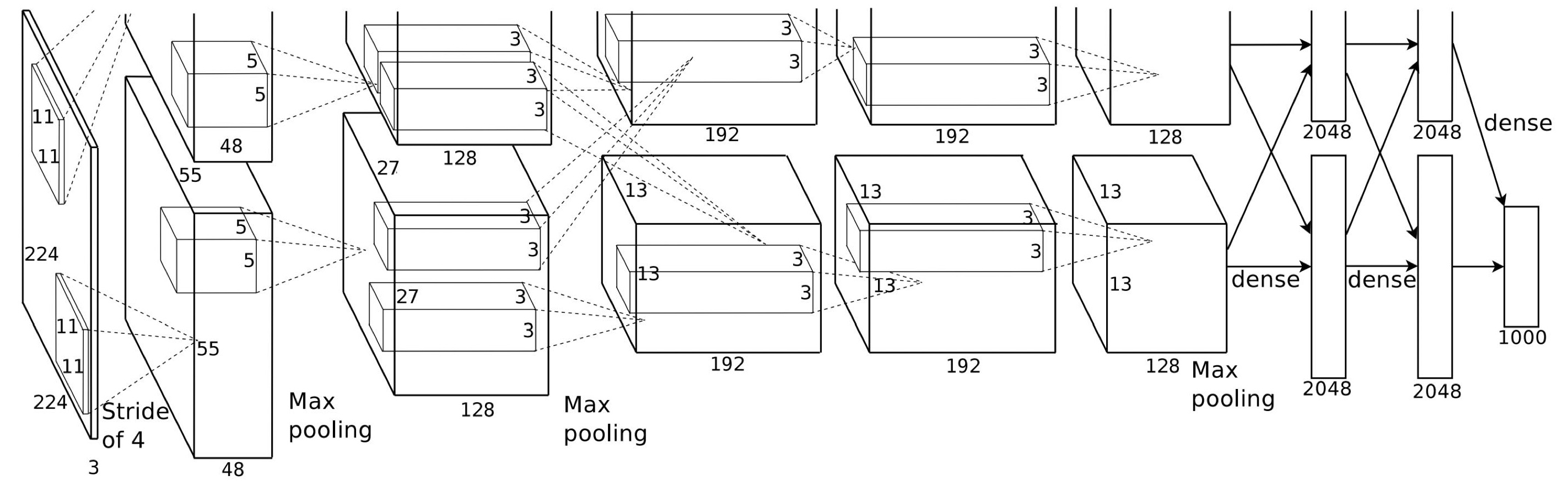
AlexNet. Neural network architecture of AlexNet (Krizhevsky et al. 2012), the winner of the ImageNet competition in 2012.
Even if we look at the early AlexNet from 2012, which made deep learning famous when it won the ImageNet competition back then, we can see the careful engineering decisions that were involved in its design. Modern networks are often even more sophisticated, and require a pipeline that spans network architecture and careful training schemes. Lots of sweat and labor had to go into producing these amazing results.

|
Engineered vs Emerged Bridges. Left: The Confederation Bridge in Canada. Right: Army ants forming a bridge.
I believe that the way we are currently doing deep learning is like engineering. I think we’re building neural network systems the same way we are building bridges and buildings. But in natural systems, where the concept of emergence plays a big role, we see complex designs that emerge due to self-organization, and such designs are usually sensitive and responsive to changes in the world around them. Natural systems adapt, and become a part of their environment.
“Bridges and buildings are all designed to be indifferent to their environment, to withstand fluctuations, not to adapt to them. The best bridge is one that just stands there, whatever the weather.”
In the last few years, I have been noticing many works in deep learning research pop up that have been using some of these ideas from collective intelligence, in particular, the area of emergent complex systems. Recently, Yujin Tang and I put together a survey paper called Collective intelligence for deep learning: A survey of recent developments about this topic, and in this post, I will summarize the key themes in our paper.
Historical Background
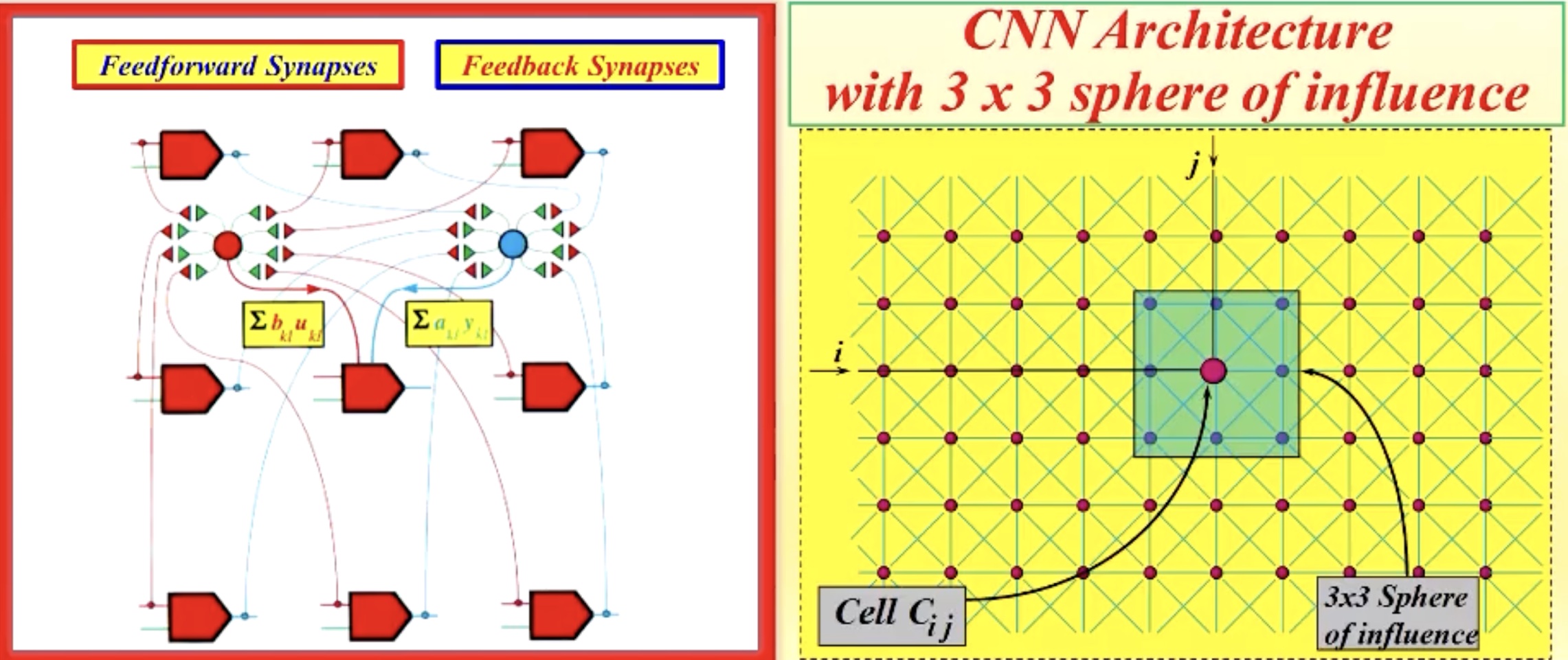
The reason deep learning took its course could be just an accidental outcome in history, and it didn’t have to be this way. In fact, in the earlier days of neural network development, from the 1980s, many groups, including the group led by Leon Chuo, a legendary electrical engineer, worked on neural networks that are much closer to natural adaptive systems. They developed something called Cellular Neural Networks, which are artificial neural network circuits with grids of artificial neurons.
|
|
Cellular Neural Networks. Each neuron in a cellular neural network would receive signals from their neighbors, perform a weighted sum operation, and apply a non-linear activation function, like how we do it today, and send off a signal for its neighbors. The difference between these networks and today’s networks is that they were built using analog circuits, meaning they would work approximately, but also at the time much faster than digital circuits. Also, the wiring of each cell (the ‘parameters’ of each cell) is exactly the same. (Source: The Chua Lectures)
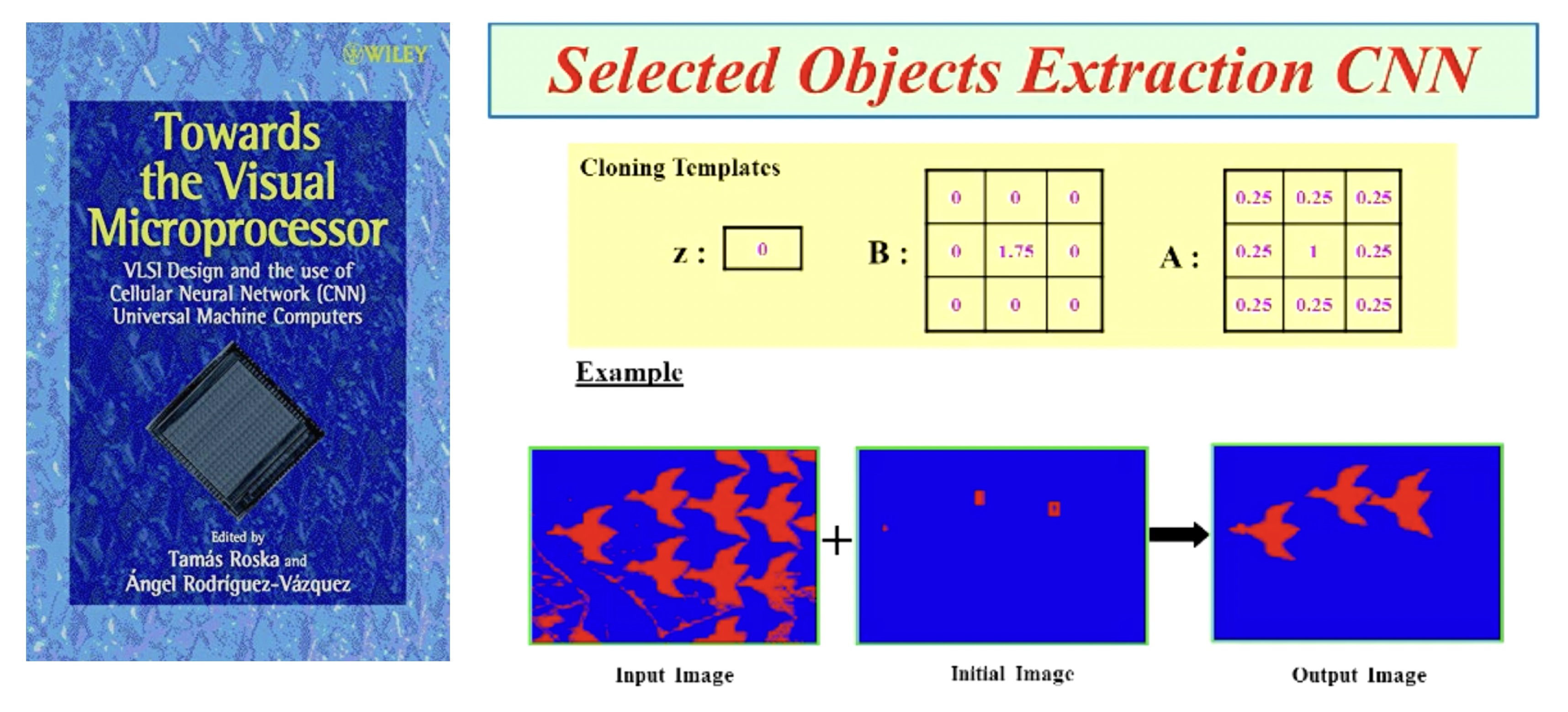
What is remarkable, is that even in the late 1980s, they have shown that these networks can produce amazing results such as object extraction. These analog networks work in nano-seconds, something that we were only able to match decades later in digital circuits. They can be programmed to do non-trivial things, like selecting all objects in a pixel image that are pointing up, and erasing all the other objects. We were able to do these tasks only decades later with deep learning:
 |
Using Cellular Neural Networks to detect all objects that are pointing upwards. Left: Input pixel image. Right: Output pixel image.
In the past few years, we have noticed many works in deep learning research that explore similar ideas as these cellular neural networks from emergent complex systems, which prompted us to write a survey. The problem is that complex systems is a huge topic, including topics that investigate behavior of actual honeybees and ant colonies, and we will limit our discussion to only a few areas focused on machine learning:
- Image Processing and Generative Models
- Deep Reinforcement Learning
- Multi-agent Learning
- Meta-learning (“Learning-to-learn”)
Image Generation
We’ll start by discussing the idea of image generation using collective intelligence. One cool example of this is a collective human intelligence: the Reddit r/Place experiment. In this community experiment, Reddit set up a 1000x1000 pixel canvas, so reddit users have to collectively create a megapixel image. But the interesting thing is the constraints Reddit had imposed: each user is only allowed to paint a single pixel every 5 minutes:
Reddit r/Place experiment: Watch a few days of activity happen in minutes.
This experiment lasted for a week, allowing millions of reddit users to draw whatever they want. Because of the time constraint imposed on each user, in order to draw something meaningful, users had to collaborate, and ultimately coordinate some strategy on discussion forums to defend their design, attack other designs, and even form alliances. It is truly an example of the creativity of collective human intelligence.
Early algorithms also computed designs on a pixel grid in a collective way. An example of such an algorithm is a Cellular Automata exemplified in Conway’s Game of Life, where the state of each pixel on a grid is computed based on a function that depends on the states of its neighbors from the previous time step, and based on simple rules, complex patterns can emerge:
 |
Conway’s Game of Life.
A recent work, Neural Cellular Automata (Mordvintsev et al., 2020), tried to extend the concept of CA’s, but replace the simple rules with a neural network, so in a sense, it is really similar to Cellular Neural Networks from the 1980s that I discussed earlier. But in this work, they apply Neural CAs to image generation, like in the Reddit r/Place example, at each time step, a pixel will be randomly chosen and updated based on the output of a single neural network function whose inputs are only the values of the pixel’s immediate neighbors.
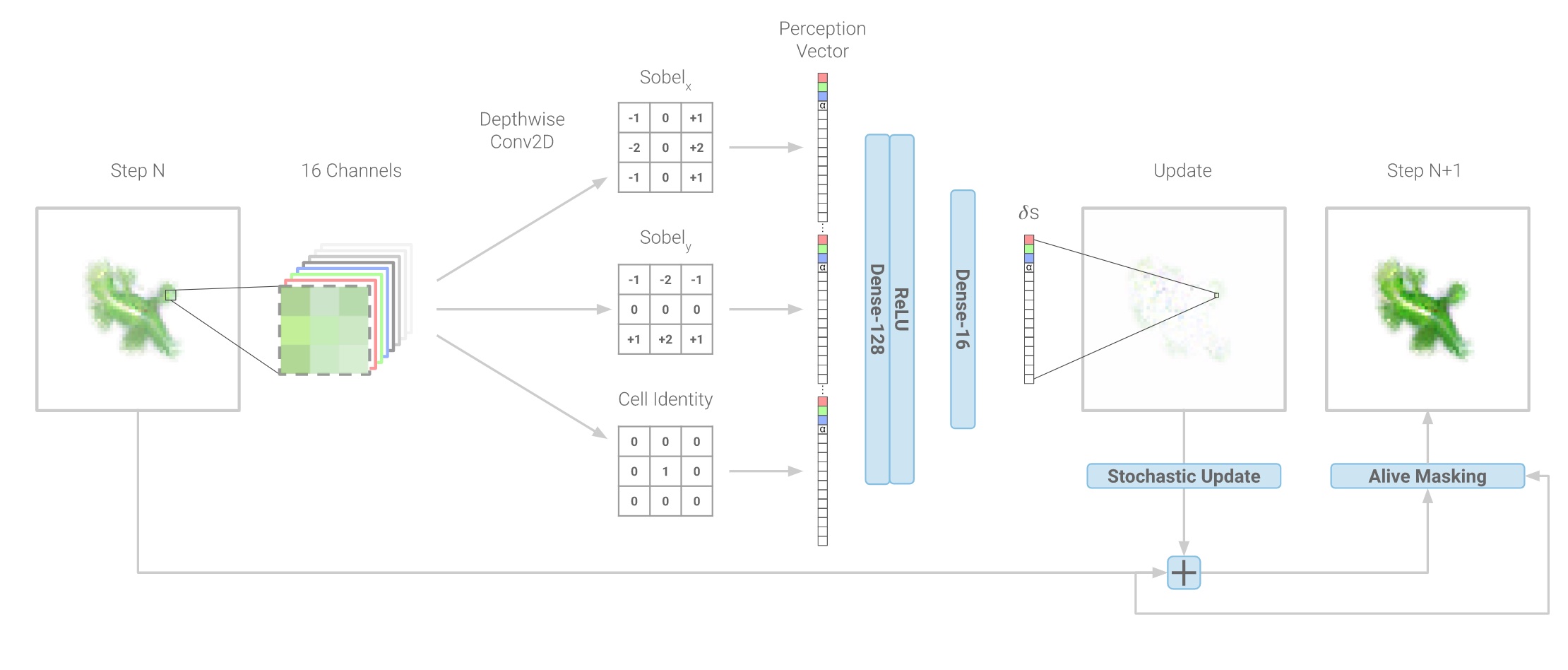 |
Neural Cellular Automata for Image Generation.
They show that a Neural CA can be trained to output any particular given design based on a sparse stochastic sampling rule and an almost empty initial canvas. Here are some examples of 3 Neural CAs producing three designs. What is remarkable about this method is that when we see some corruption in the image, the algorithm would attempt to regenerate the corrupt part automatically in its own way.
|
|
Neural Cellular Automata regenerating corrupted images.
Neural CA’s can also perform prediction tasks in a collective fashion. For example, they can be applied to classify MNIST digits, but the difference here is that each pixel must produce its own prediction based on its own pixel, and predictions from its immediate neighbors, so its own prediction will also influence the predictions of its neighbors too and change their opinions over time, like in a democratic society. Over time, usually some consensus is made across the collection of pixels, but sometimes, we can see interesting effects, like if the digit is written in a weird way, there will be different steady states of predictions across different regions of the digit.
|
|
Self-classifying MNIST Digits. A Neural Cellular Automata trained to recognize MNIST digits created by (Randazzo et al. 2020) is also available as an interactive web demo. Each cell is only allowed to see the contents of a single pixel and communicate with its neighbors. Over time, a consensus will be formed as to which digit is the most likely pixel, but interestingly, disagreements may result depending on the location of the pixel where the prediction is made.
Neural CA’s are not confined to generating pixels. They can also generate voxels and 3D shapes. Recent work even used Neural CA to produce designs in Minecraft, which are sort of like voxels. They can produce things like buildings and trees, but what’s most interesting is that, since some components inside Minecraft are active rather than passive, they can also generate functional machines with behavior.

|
Neural CAs have also been applied to the regeneration of Minecraft entities. In this work Sudhakaran, 2021, the authors’ formulation enabled the regeneration of not only Minecraft buildings, trees, but also simple functional machines in the game such as worm-like creatures that can even regenerate into two distinct creatures when cut in half.
Here, they show that when one of these functional machines get cut in half, each half can regenerate itself morphogenetically, to end up with two functional machines.
|
|
Morphogenesis. Aside from regeneration, the Neural CA system in Minecraft is able to regrow parts of simple functional machines (such as a virtual creature in the game). They demonstrate a morphogenetic creature growing into 2 distinct creatures when cut in half in Minecraft.
Deep Reinforcement Learning
Another popular area within Deep Learning is to train neural networks with reinforcement learning for tasks like locomotion control. Here are a few examples of these Mujoco Humanoid benchmark environments and their state-of-the-art solutions:
|
|
State-of-the-art Mujoco Humanoids. You may not like it, but this is what peak performance looks like.
What usually happens is that all of the input observation states (in the case of the humanoid, we have 376 observations) are fed into a deep neural network, the “policy”, that will output the 17 actions required to control the actuators of the humanoid for it to move forward. Typically, these policy networks tend to overfit the training environment, so you end up with solutions that only work for this exact design and simulation environment.
We’ve seen some interesting works recently that look at using a collective controller approach for these problems. In particular, in Huang et al., 2020, rather than having one policy network take all of the inputs and output all of the actions, here, they use a single shared policy for every actuator in the agent, effectively decomposing an agent into a collection of agents connected by limbs:
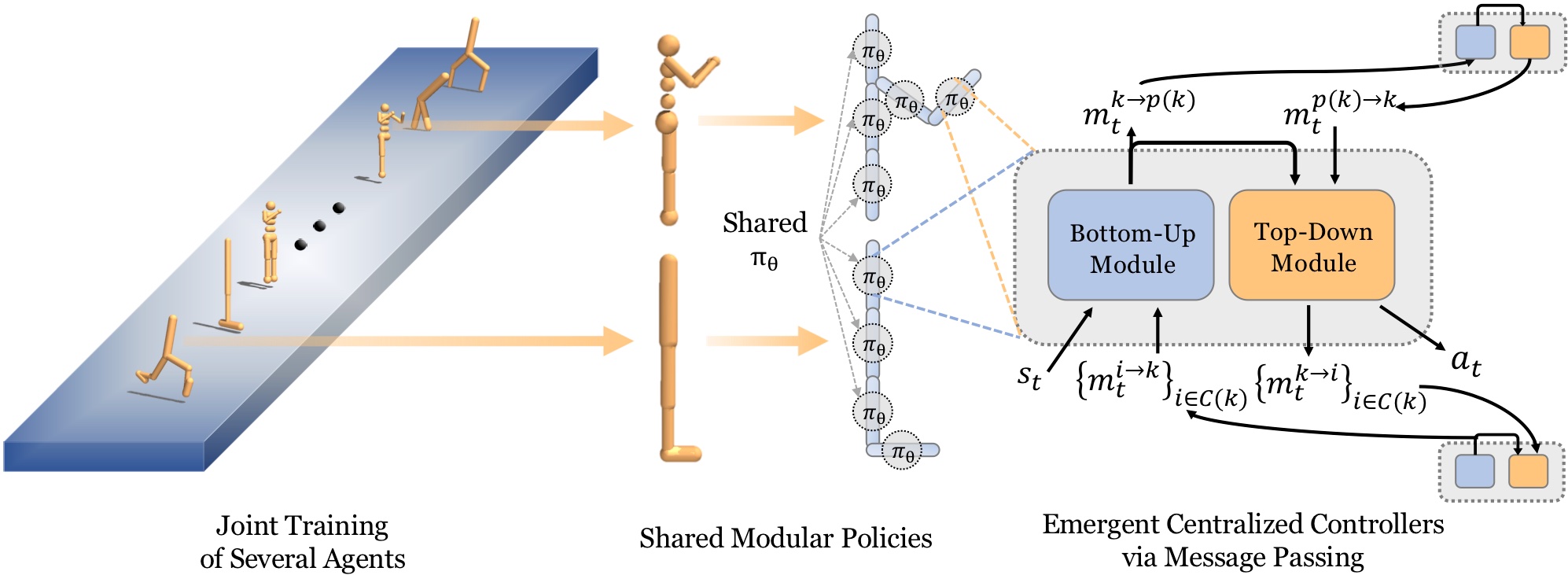
|
Traditional RL methods train a specific policy for a particular robot with a fixed morphology. But recent work, like the one shown here by Huang et al. 2020 attempts to train a single modular neural network responsible for controlling a single part of a robot. The resulting global policy of each robot is thus the result of the coordination of these identical modular neural networks, something which has emerged from local interaction. This system can generalize across a variety of different skeletal structures, from hoppers to quadrupeds, and even to some unseen morphologies.
These policies can communicate bi-directionally with their neighbors, so over time, a global policy can emerge from local interaction. Not only do they train this single policy for one agent design, but it must work across dozens of designs in a training set, so here, every one of these agents are controlled by the same policy that governs each actuator:
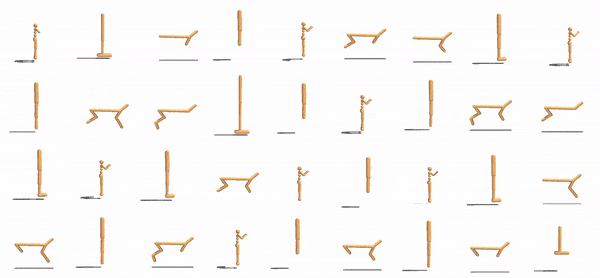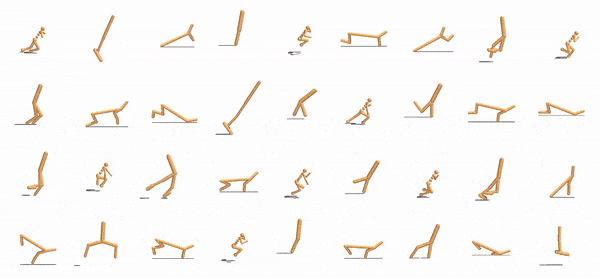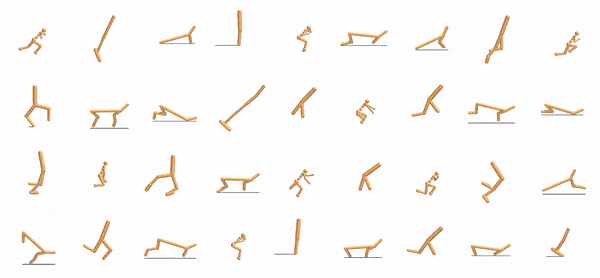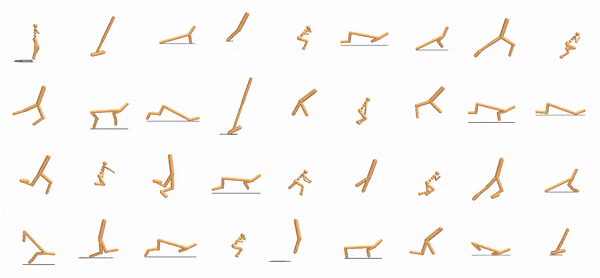
|
One identical neural network controlling every actuator must work across all of these designs.
They show that this type of collective system has some zero-shot generalization capabilities and can also control agents with not only different design variations with different limb lengths and masses, but also novel designs not in the training set, and also deal with unseen challenges:
|
|
Well, why rely on a fixed design? Another work, Pathak et al., 2019 looks at getting every limb limb to figure out a way to self-assemble, and learn a design to perform tasks like balancing and locomotion:
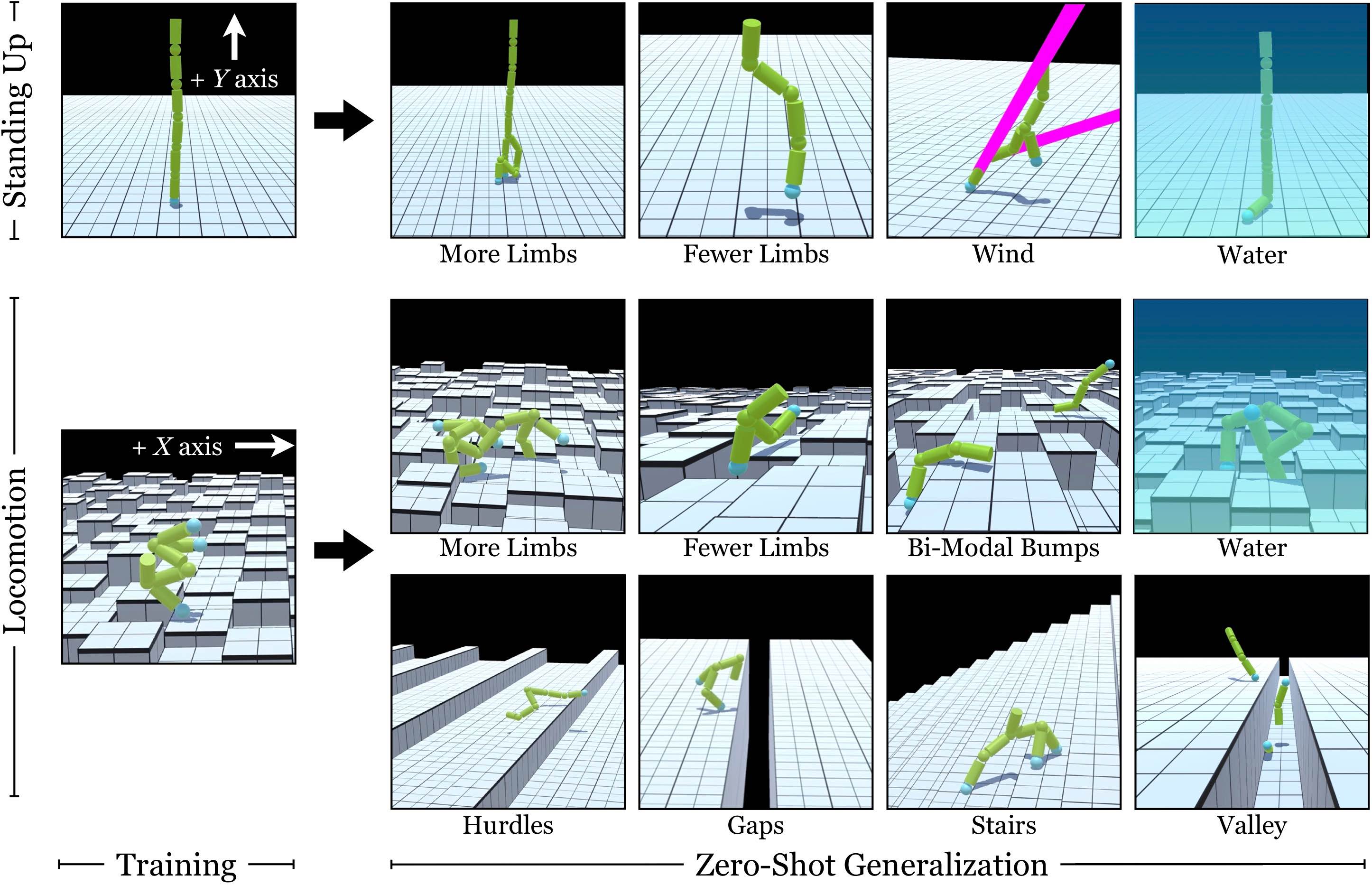
|
Self-assembling limbs. Self-organization also enables systems in RL environments to self-configure its own design for a given task. In Pathak et al., 2019, the authors explored such dynamic and modular agents and showed that they can generalize to not only unseen environments, but also to unseen morphologies composed of additional modules.
They show that this approach can generalize to cases even when you have double or half the number of limbs the system was trained on–something simply not possible with traditional deep RL. Even a system trained with traditional deep RL would work, but the self-assembling solutions consistently prove to be more robust to unseen challenges like wind, or in the case of locomotion, handle new types of terrain such as hurdles and stairs:
This type of collective policy making can also be applied to image-based RL tasks too. In a recent paper that Yujin Tang and I presented at NeurIPS, we looked at feeding each patch from a video feed into identical sensory neuron units, and these sensory neurons must figure out the context of its own input channel, and then self-organize using an attention mechanism for communication, to collectively output motor commands for the agent. This allows the agent to still work even when the patches on the screen are all shuffled:
Sensory Substitution. Using the properties of self-organization and attention, our paper, Tang and Ha, 2021, investigated RL agents that treat their observations as an arbitrarily ordered, variable-length list of sensory inputs. Here, they partition the input in visual tasks such as CarRacing into a 2D grid of small patches, and shuffled their ordering. Each sensory neuron in the system receives a stream of a particular patch of pixels, and through coordination, must complete the task at hand. This agent works with new backgrounds that it hasn’t seen during training (it’s only seen the green grass background).
The work is inspired by the idea of sensory substitution, where different parts of the brain can be retrained to process different sensory modalities, enabling us to adapt our senses to crucial information sources.
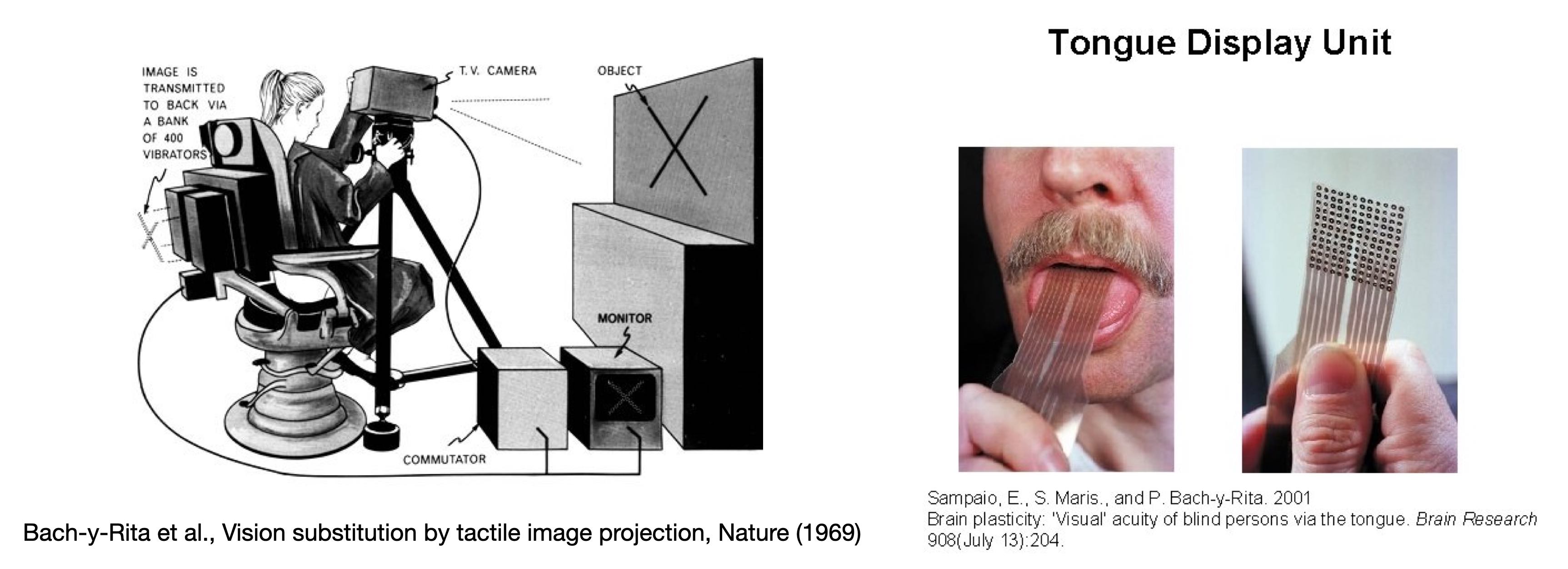
|
Neuroscientist Paul Bach-y-rita (1934-2006) is known as “the father of sensory substitution”.
This method works on non-vision tasks too. When we apply this method to a locomotion task, like this ant agent, we can shuffle the ordering of the 28 inputs quite frequently, and our agent will quickly adjust to a dynamic observation space:
|
|
Permutation invariant reinforcement learning agents adapting to sensory substitutions. The ordering of the ant’s 28 observations are randomly shuffled every 200 time-steps. Unlike the standard policy, our policy is not affected by the suddenly permuted inputs.
We can get the agent to play a Puzzle Pong game where the patches are constantly reshuffled, and we show that the system can also work with partial information, like with only 70% of the patches, which are all shuffled:
Multi-agent learning
The earlier reinforcement learning examples were mainly about decomposing a single agent into a smaller collection of agents. But what we do know from complex systems is that emergence often occurs at much larger scales than 10 or 20 agents. Perhaps we need a collection of thousands or more individual agents to interact meaningfully for complex “super organisms” to emerge.
A few years back there was a paper that looked at taking advantage of hardware accelerators, like GPUs, to enable significant scaling up of multi-agent reinforcement learning. In this work called MAgent (Zheng et al., 2018), they proposed a framework to get up to a million agents, though simple ones, to engage in various grid world multi-agent environments, and furthermore, they can have one population of agents pit against another population of agents in a collective self-play manner.
MAgent (Zheng et al., 2018) is a set of environments where large numbers of pixel agents in a gridworld interact in battles or other competitive scenarios. Unlike most platforms that focus on RL research with a single agent or only few agents, their aim is to support RL research that scales up to millions of agents.
The hardware revolution brought about by deep learning can enable us to take advantage of the hardware and use them to train truly large scale collective behavior. In some of these experiments, they observe predator-prey loops, and encirclement tactics emerge from truly large-scale multi-agent reinforcement learning. These macro-level collective intelligence will probably not emerge from traditional small-scale multi-agent environments:
I would like to note that this work was from 2018, and hardware acceleration progress has only exponentially increased since then. A recent demo from NVIDIA last year showcased a physics engine that can now handle thousands of agents acting in a realistic physics simulation, unlike the simple gridworld environment. I believe that in the future, we could see really interesting studies of emergent behavior using these newer technologies.
Recent advances in GPU hardware enables realistic 3D simulation of thousands of robot models, such as the one shown in this figure by Rudin et al. 2021. Such advances open the door for large-scale 3D simulation of artificial agents that can interact with each other and collectively develop intelligent behavior.
Meta-Learning
These increases in compute capabilities won’t stop at simulation. I’ll end with a discussion on how collective behavior is being applied to meta-learning. We can think of an artificial neural network as a collection of neurons and synapses, each of which can be modeled as an individual agent, and collectively, these agents all interact inside a system where the ability to learn is an emergent property.
Currently, our concept of artificial neural networks are simply weight matrices between nodes with a non-linear activation function. But with the extra compute, we can also explore really interesting directions where we can simulate generalized version of neural networks, where perhaps every “neuron” is implemented as an identical recurrent neural network (which can in principle compute anything). I remember several neuroscience papers exploring this theme, see neuroscientist Mark Humphries’s excellent blog post.
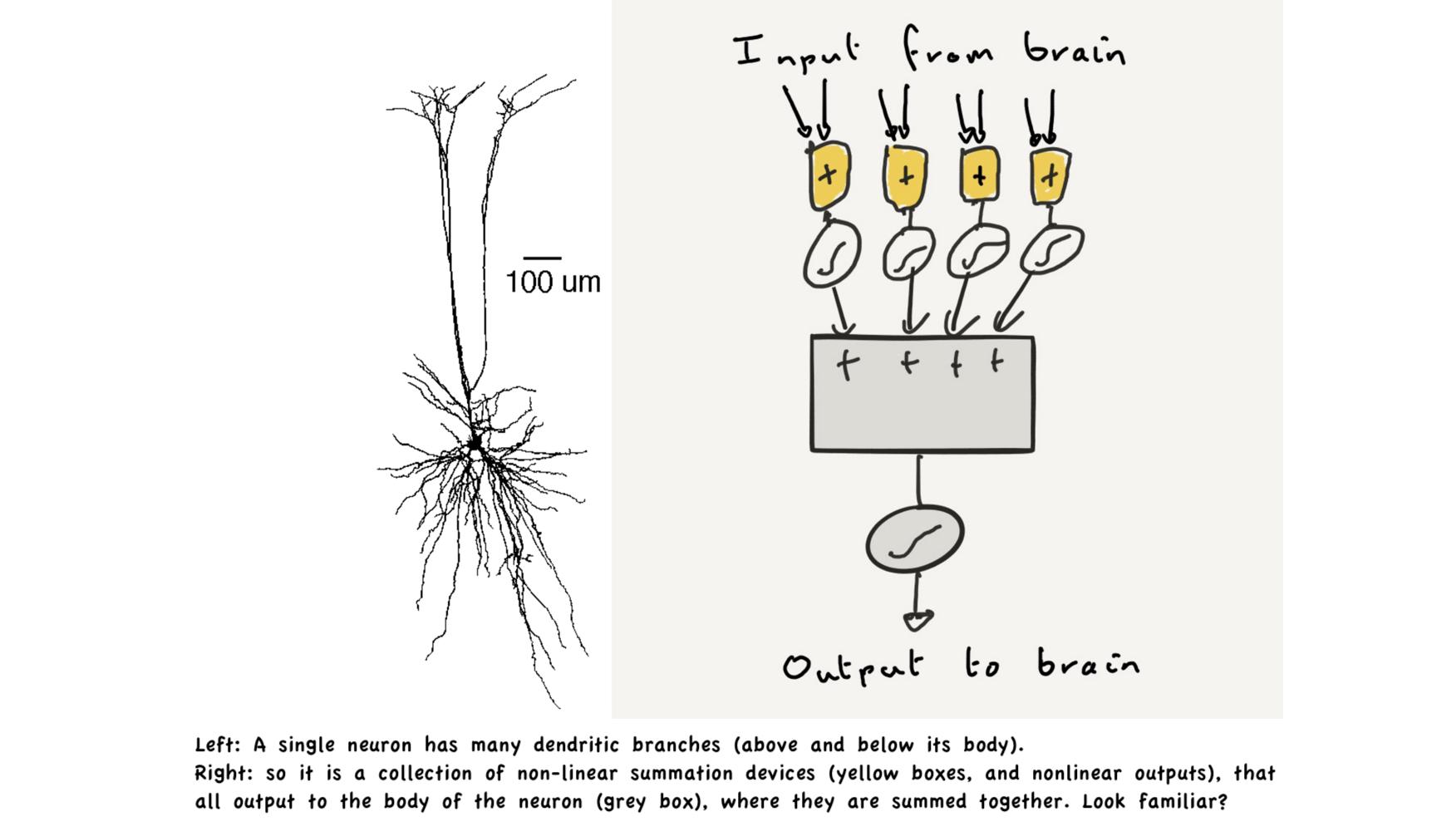
|
Each “Neuron” is an Artificial Neural Network. “If we think the brain is a computer, because it is like a neural network, then now we must admit that individual neurons are computers too. All 17 billion of them in your cortex; perhaps all 86 billion in your brain.” — Mark Humphries
Rather than neurons though, recently, we have seen some pretty ambitious works, modeling the synapse as a recurrent neural network. This is because when we look at how a standard neural network is trained, we go through a forward pass of the network to forward propagate the inputs of the network to the output, and then we use the back propagation algorithm to “back propagate” the error signals back from the output layer to the input layer, using gradients to adjust the weights, so in principle, an RNN synapse can also learn something like the backpropagation rule, or perhaps something even better.
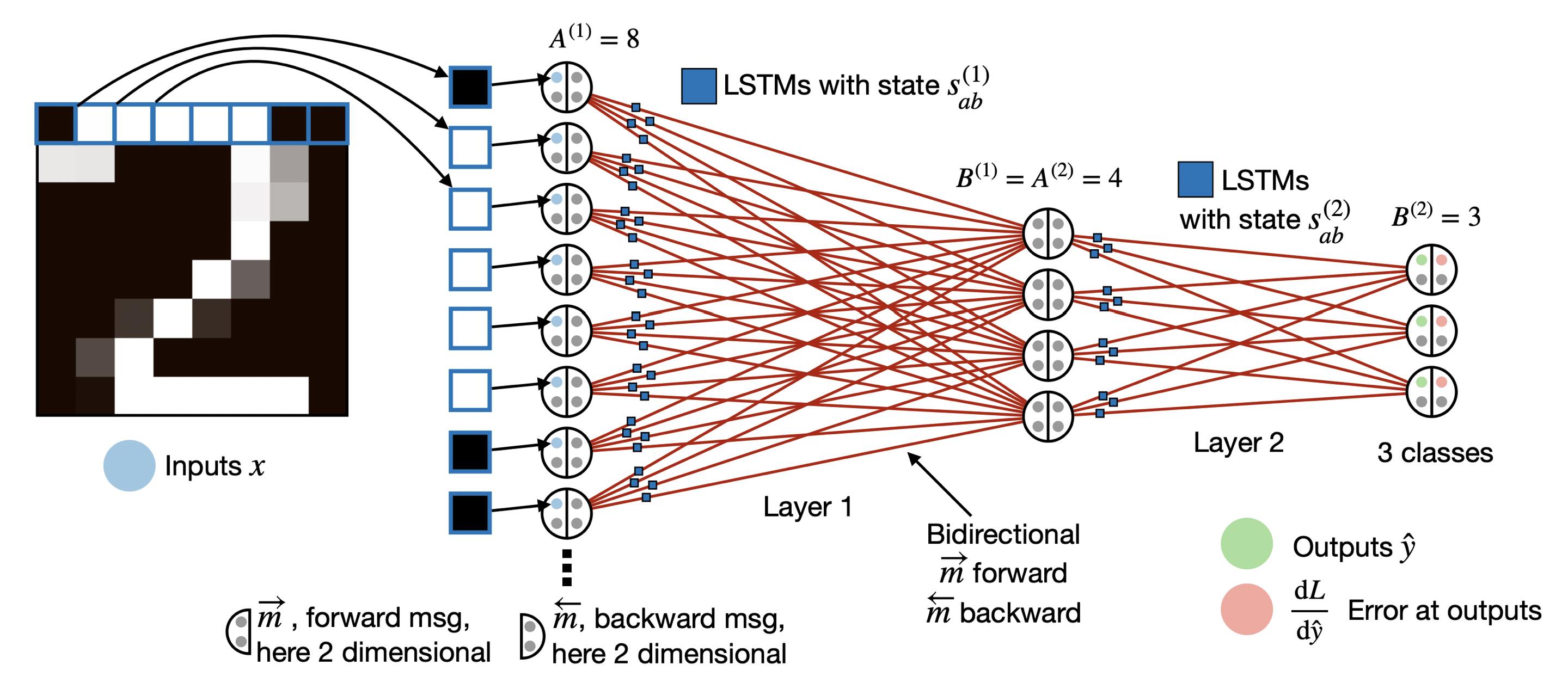
|
Each Synapse is a Recurrent Neural Network. Recent work by Sandler et al., 2021 and Kirsch and Schmidhuber, 2020 attempt to generalize the accepted notion of artificial neural networks, where each neuron can hold multiple states rather than a scalar value, and each synapse function bi-directionally to facilitate both learning and inference. In this figure, (Kirsch et al. 2021) use an identical recurrent neural network (RNN) (with different internal hidden states) to model each synapse, and show that the network can be trained by simply running the RNNs forward, without using backpropagation.
So rather than relying on this forward and back propagation, we can model each synapse of a neural network with a recurrent neural network, which is a universal computer, to learn how to best forward and back propagate the signals, or learning how to learn. The “hidden states” of each RNN would essentially define what the “weights” are in a highly plastic way.
Recent works, Sandler et al., 2021 and Kirsch and Schmidhuber, 2020, have shown that these approaches are a generalization of back propagation. They can even experimentally train these meta learning network exactly replicate perfectly the back propagation operation and perform stochastic gradient descent. But more importantly, they can evolve learning rules that can learn more efficiently than stochastic gradient descent, or even ADAM.
In the following experiment, Kirsch and Schmidhuber, 2020 trained this type of meta learning system, called variable shared meta learner, the blue line, to learn a learning rule using only the MNIST dataset, where the learning rule here outperforms backprop SGD and Adam baselines, which is expected since the learning rule learned is fine-tuned to the MNIST dataset. But when they test the learning rule on a new dataset, like Fashion-MNIST, they see similar performance gains:
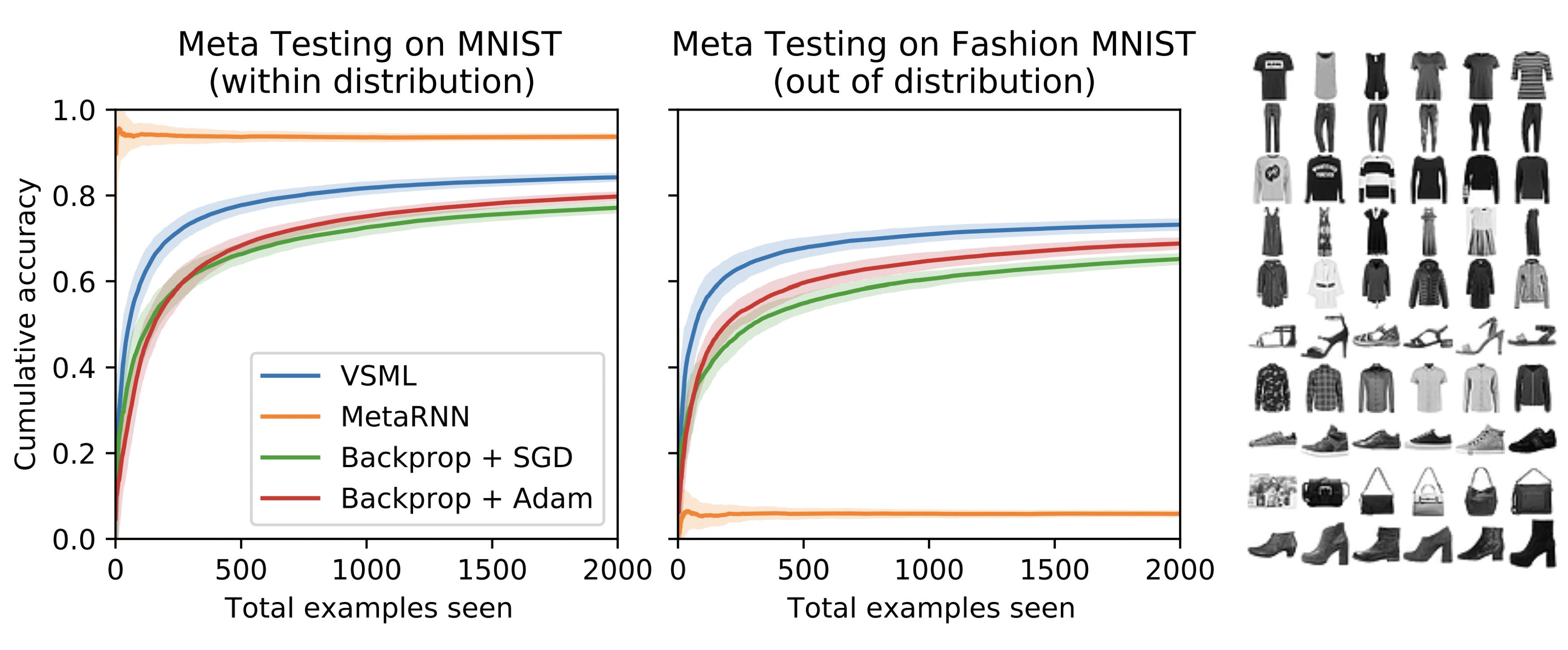
|
These works are still in their early stages, but I think such approaches of modeling neural networks as a truly collective set of identical neurons or synapses, rather than fixed unique weights, are a really promising direction that will really change the sub-field of meta-learning.
Summary
Neural network systems are highly complex. We may never be able to truly understand how they work at the level as simple idealized systems that can be explained (and predicted) with relatively simple physical laws. I believe that deep learning research can benefit from looking at neural network systems: their construction, training, and deployment, as complex systems. I hope this blog post is a useful survey of several ideas from complex systems that makes neural network systems more robust and adaptive to changes to their environments.
If you are interested in reading more, please check out our paper published in Collective Intelligence.
Citation
If you find this blog post useful, please cite our paper as:
@article{doi:10.1177/26339137221114874,
author = {David Ha and Yujin Tang},
title ={Collective intelligence for deep learning: A survey of recent developments},
journal = {Collective Intelligence},
volume = {1},
number = {1},
year = {2022},
doi = {10.1177/26339137221114874},
URL = {https://doi.org/10.1177/26339137221114874},
}