Update: PyTorch Implementation of the same notebook available here.
A short while ago Google open-sourced TensorFlow, a library designed to allow easy computations on graphs. The main applications are targeted for deep learning, as neural networks are represented as graphs. I’ve spent a few days reading their APIs and tutorials and I like what I see. Although other libraries offer similar features such as GPU computations and symbolic differentiation, the cleanliness of the API, and familiarity of the IPython stack makes it appealing to use.
In this post I try to use TensorFlow to implement the classic Mixture Density Networks (Bishop ’94) model. I have implemented MDN’s before in an earlier blog post. This is my first attempt at learning to use TensorFlow, and there are probably much better ways to do many things, so let me know in the comment section!
Simple Data Fitting with TensorFlow
To get started, let’s try to quickly build a neural network to fit some fake data. As neural nets of even one hidden layer can be universal function approximators, we can see if we can train a simple neural network to fit a noisy sinusoidal data, like this ( is just standard gaussian random noise):
We can define a loss function as the sum of square error of the output vs the data (we can add regularisation if we want).
lossfunc=tf.nn.l2_loss(y_out-y);
We will also define a training operator that will tell TensorFlow to minimise the loss function later. With just a line, we can use the fancy RMSProp gradient descent optimisation method.
To start using TensorFlow to compute things, we have to define a session object. In an IPython shell, we use InteractiveSession. Afterwards, we need to run a command to initialise all variables, where the computation graph will also be built inside TensorFlow.
We will run gradient descent for 1000 times to minimise the loss function with the data fed in via a dictionary. As the dataset is not large, we won’t use mini batches. After the below is run, the weight and bias parameters will be auto stored in their respective tf.Variable objects.
What I like about the API is that we can simply use sess.run() again to generate data from any operator or node within the network. So after the training is finished, we can just use the trained model, and another call to sess.run() to generate the predictions, and plot the predicted data vs the training data set.
We should also close() the session afterwards to free resources when we are done with this exercise.
We see that the neural network can fit this sinusoidal data quite well, as expected. However, this type of fitting method only works well when the function we want to approximate with the neural net is a one-to-one, or many-to-one function. Take for example, if we invert the training data:
If we were to use the same method to fit this inverted data, obviously it wouldn’t work well, and we would expect to see a neural network trained to fit only to the square mean of the data.
Our current model only predicts one output value for each input, so this approach will fail miserably. What we want is a model that has the capacity to predict a range of different output values for each input. In the next section we implement a Mixture Density Network (MDN) to do achieve this task.
Mixture density networks
Mixture Density Networks (MDNs), developed by Christopher Bishop in the 90’s, attempt to address this problem. The approach is rather to have the network predict a single output value, the network is to predict an entire probability distribution for the output. This concept is quite powerful, and can be employed many current areas of machine learning research. It also allows us to calculate some sort of confidence factor in the predictions that the network is making.
The inverse sinusoidal data we chose is not just for a toy problem, as there are applications in the field of robotics, for example, where we want to determine which angle we need to move the robot arm to achieve a target location. MDNs can also used to model handwriting, where the next stroke is drawn from a probability distribution of multiple possibilities, rather than sticking to one prediction.
Bishop’s implementation of MDNs will predict a class of probability distributions called Mixture Gaussian distributions, where the output value is modelled as a sum of many gaussian random values, each with different means and standard deviations. So for each input , we will predict a probability distribution function (pdf) of that is a probability weighted sum of smaller gaussian probability distributions.
Each of the parameters of the distribution will be determined by the neural network, as a function of the input . There is a restriction that the sum of add up to one, to ensure that the pdf integrates to 100%. In addition, must be strictly positive.
In our implementation, we will use a neural network of one hidden later with 24 nodes, and also generate 24 mixtures, hence there will be 72 actual outputs of our neural network of a single input. Our definition will be split into 2 parts:
is a vector of 72 values that will be then splitup into three equal parts, , , and
The parameters of the pdf will be defined as below to satisfy the earlier conditions:
are essentially put into a softmax operator to ensure that the sum adds to one, and that each mixture probability is positive. Each will also be positive due to the exponential operator. It gets deeper than this though! In Bishop’s paper, he notes that the softmax and exponential terms have some theoretical interpretations from a Bayesian framework way of looking at probability. Note that in the actual softmax code, the largest value will divide both numerator and denominator to avoid exp operator easily blowing up. In TensorFlow, the network is described below:
NHIDDEN=24STDEV=0.5KMIX=24# number of mixturesNOUT=KMIX*3# pi, mu, stdevx=tf.placeholder(dtype=tf.float32,shape=[None,1],name="x")y=tf.placeholder(dtype=tf.float32,shape=[None,1],name="y")Wh=tf.Variable(tf.random_normal([1,NHIDDEN],stddev=STDEV,dtype=tf.float32))bh=tf.Variable(tf.random_normal([1,NHIDDEN],stddev=STDEV,dtype=tf.float32))Wo=tf.Variable(tf.random_normal([NHIDDEN,NOUT],stddev=STDEV,dtype=tf.float32))bo=tf.Variable(tf.random_normal([1,NOUT],stddev=STDEV,dtype=tf.float32))hidden_layer=tf.nn.tanh(tf.matmul(x,Wh)+bh)output=tf.matmul(hidden_layer,Wo)+bodefget_mixture_coef(output):out_pi=tf.placeholder(dtype=tf.float32,shape=[None,KMIX],name="mixparam")out_sigma=tf.placeholder(dtype=tf.float32,shape=[None,KMIX],name="mixparam")out_mu=tf.placeholder(dtype=tf.float32,shape=[None,KMIX],name="mixparam")out_pi,out_sigma,out_mu=tf.split(1,3,output)max_pi=tf.reduce_max(out_pi,1,keep_dims=True)out_pi=tf.sub(out_pi,max_pi)out_pi=tf.exp(out_pi)normalize_pi=tf.inv(tf.reduce_sum(out_pi,1,keep_dims=True))out_pi=tf.mul(normalize_pi,out_pi)out_sigma=tf.exp(out_sigma)returnout_pi,out_sigma,out_muout_pi,out_sigma,out_mu=get_mixture_coef(output)
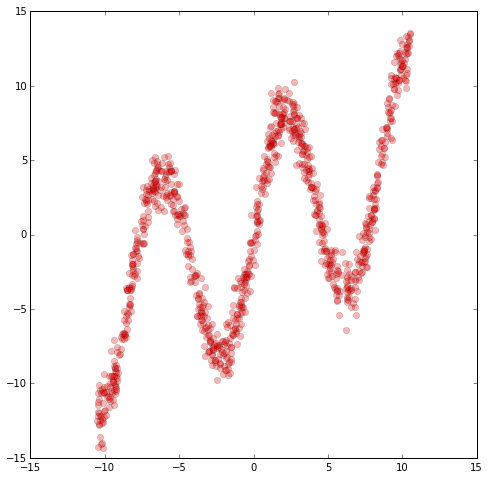
Let’s define the inverted data we want to train our MDN to predict later. As this is a more involved prediction task, I used a higher number of samples compared to the simple data fitting task earlier.
NSAMPLE=2500y_data=np.float32(np.random.uniform(-10.5,10.5,(1,NSAMPLE))).Tr_data=np.float32(np.random.normal(size=(NSAMPLE,1)))# random noisex_data=np.float32(np.sin(0.75*y_data)*7.0+y_data*0.5+r_data*1.0)plt.figure(figsize=(8,8))plt.plot(x_data,y_data,'ro',alpha=0.3)plt.show()
We cannot simply use the min square error L2 lost function in this task the output is an entire description of the probability distribution. A more suitable loss function is to minimise the logarithm of the likelihood of the distribution vs the training data:
So for every point in the training data set, we can compute a cost function based on the predicted distribution versus the actual points, and then attempt the minimise the sum of all the costs combined. To those who are familiar with logistic regression and cross entropy minimisation of softmax, this is a similar approach, but with non-discretised states.
We implement this cost function in TensorFlow below as an operation:
oneDivSqrtTwoPI=1/math.sqrt(2*math.pi)# normalisation factor for gaussian, not needed.deftf_normal(y,mu,sigma):result=tf.sub(y,mu)result=tf.mul(result,tf.inv(sigma))result=-tf.square(result)/2returntf.mul(tf.exp(result),tf.inv(sigma))*oneDivSqrtTwoPIdefget_lossfunc(out_pi,out_sigma,out_mu,y):result=tf_normal(y,out_mu,out_sigma)result=tf.mul(result,out_pi)result=tf.reduce_sum(result,1,keep_dims=True)result=-tf.log(result)returntf.reduce_mean(result)lossfunc=get_lossfunc(out_pi,out_sigma,out_mu,y)train_op=tf.train.AdamOptimizer().minimize(lossfunc)
We will train the model below, while collecting the progress of the loss function over training iterations. TensorFlow offers some useful tools to visualise training data progress but we didn’t use them here.
sess=tf.InteractiveSession()sess.run(tf.initialize_all_variables())NEPOCH=10000loss=np.zeros(NEPOCH)# store the training progress here.foriinrange(NEPOCH):sess.run(train_op,feed_dict={x:x_data,y:y_data})loss[i]=sess.run(lossfunc,feed_dict={x:x_data,y:y_data})
As a side note, the impressive thing is that TensorFlow automatically calculated the gradients of the log likelihood cost functions and applied those gradients in the optimisation. For this problem, actually there are very optimised gradient formulas available (see derivations in Bishop’s original paper, equations 33-39), and I highly doubt the gradient formula TensorFlow calculated automatically will be as optimised and elegant, so there would be room for performance improvements by building a custom operator into TensorFlow with the pre-optimised gradient formulas for this loss function, like they have done for the cross entropy loss function. I had implemented before the optimised closed-form gradient formulas with all the numerical gradient testing that came with it – if you want to implement it, please make sure you do the gradient testing! It is difficult to get right the first time.
Let’s plot the progress of the training, and see if the cost decreases over iterations:
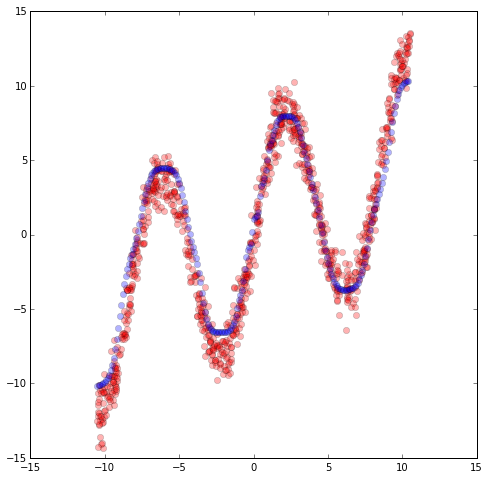
We found that it more or less stopped improving after 6000 iterations or so. The next thing we want to do, is to have the model generate distributions for us, say, across a bunch of points along the x-axis, and then for each distribution, draw 10 points randomly from that distribution, to produce ensembles of generated data on the y-axis. This gives us a feel of whether the pdf generated matches the training data.
To sample a mixed gaussian distribution, we randomly select which distribution based on the set of probabilities, and then proceed to draw the point based off the gaussian distribution.
x_test=np.float32(np.arange(-15,15,0.1))NTEST=x_test.sizex_test=x_test.reshape(NTEST,1)# needs to be a matrix, not a vectordefget_pi_idx(x,pdf):N=pdf.sizeaccumulate=0foriinrange(0,N):accumulate+=pdf[i]if(accumulate>=x):returniprint'error with sampling ensemble'return-1defgenerate_ensemble(out_pi,out_mu,out_sigma,M=10):NTEST=x_test.sizeresult=np.random.rand(NTEST,M)# initially random [0, 1]rn=np.random.randn(NTEST,M)# normal random matrix (0.0, 1.0)mu=0std=0idx=0# transforms result into random ensemblesforjinrange(0,M):foriinrange(0,NTEST):idx=get_pi_idx(result[i,j],out_pi[i])mu=out_mu[i,idx]std=out_sigma[i,idx]result[i,j]=mu+rn[i,j]*stdreturnresult
In the above graph, we plot out the generated data we draw out from the MDN distribution, in blue, and plot it over the original training data in red. Apart from a few out liers, the distributions seem to match the data. We can also plot a graph of as well, and we see what the neural network is sort of doing. For every point on the x-axis, there are multiple lines or states where may be, and we select these states with probabilities defined by .
Lastly, if we want, we can try to draw the entire mixture pdf at each point on the x-axis to get a heatmap.
x_heatmap_label=np.float32(np.arange(-15,15,0.1))y_heatmap_label=np.float32(np.arange(-15,15,0.1))defcustom_gaussian(x,mu,std):x_norm=(x-mu)/stdresult=oneDivSqrtTwoPI*math.exp(-x_norm*x_norm/2)/stdreturnresultdefgenerate_heatmap(out_pi,out_mu,out_sigma,x_heatmap_label,y_heatmap_label):N=x_heatmap_label.sizeM=y_heatmap_label.sizeK=KMIXz=np.zeros((N,M))# initially random [0, 1]mu=0std=0pi=0# transforms result into random ensemblesforkinrange(0,K):foriinrange(0,M):pi=out_pi[i,k]mu=out_mu[i,k]std=out_sigma[i,k]forjinrange(0,N):z[N-j-1,i]+=pi*custom_gaussian(y_heatmap_label[j],mu,std)returnzdefdraw_heatmap(xedges,yedges,heatmap):extent=[xedges[0],xedges[-1],yedges[0],yedges[-1]]plt.figure(figsize=(8,8))plt.imshow(heatmap,extent=extent)plt.show()z=generate_heatmap(out_pi_test,out_mu_test,out_sigma_test,x_heatmap_label,y_heatmap_label)draw_heatmap(x_heatmap_label,y_heatmap_label,z)
Some Closing Thoughts
sess.close()
I think MDN’s are a great way to model data, especially if what we are modelling have either multiple states, or is inherently a random variable that cannot be predicted with absolute certainty. I believe even simple single-layer MDN’s like these can be put to good use, as they are so simple to build!
TensorFlow has a solid and clean API which will make implementing and testing machine learning algorithms more efficient, especially combined with the IPython stack.
There are many issues related to performance, which needs to be ironed out. Also, although the library can be used in theory for distributed computing, so far only the non-distributed version has been open sourced.
Symbolic differentiation is great, but at some point would be nice to be able to manually implement efficient solved derivative formulas in a simpler way than adding an operation and having the need to recompile the entire library. That being said, TensorFlow’s symbolic operation seems much faster than Theano’s compiling process.
The full IPython notebook for this post can be found here
This blog post was exported from an IPython notebook. Here is the link to the original notebook, for better viewing on a non-mobile device.

 is just standard gaussian random noise):
is just standard gaussian random noise):




 , we will predict a probability distribution function (pdf) of
, we will predict a probability distribution function (pdf) of  that is a probability weighted sum of smaller gaussian probability distributions.
that is a probability weighted sum of smaller gaussian probability distributions.
 of the distribution will be determined by the neural network, as a function of the input
of the distribution will be determined by the neural network, as a function of the input  add up to one, to ensure that the pdf integrates to 100%. In addition,
add up to one, to ensure that the pdf integrates to 100%. In addition,  must be strictly positive.
must be strictly positive.
 is a vector of 72 values that will be then splitup into three equal parts,
is a vector of 72 values that will be then splitup into three equal parts,  ,
,  , and
, and 

 are essentially put into a softmax operator to ensure that the sum adds to one, and that each mixture probability is positive. Each
are essentially put into a softmax operator to ensure that the sum adds to one, and that each mixture probability is positive. Each  will also be positive due to the exponential operator. It gets deeper than this though! In Bishop’s paper, he notes that the softmax and exponential terms have some theoretical interpretations from a Bayesian framework way of looking at probability. Note that in the actual softmax code, the largest value will divide both numerator and denominator to avoid
will also be positive due to the exponential operator. It gets deeper than this though! In Bishop’s paper, he notes that the softmax and exponential terms have some theoretical interpretations from a Bayesian framework way of looking at probability. Note that in the actual softmax code, the largest value will divide both numerator and denominator to avoid 
![CostFunction(y | x) = -\log[ \sum_{k}^K \Pi_{k}(x) \phi(y, \mu(x), \sigma(x)) ]]( /wp-content/ql-cache/quicklatex.com-69b07f5996898963d10ff73e13f45f7b_l3.png "Rendered by QuickLaTeX.com")
 point in the training data set, we can compute a cost function based on the predicted distribution versus the actual points, and then attempt the minimise the sum of all the costs combined. To those who are familiar with logistic regression and cross entropy minimisation of softmax, this is a similar approach, but with non-discretised states.
point in the training data set, we can compute a cost function based on the predicted distribution versus the actual points, and then attempt the minimise the sum of all the costs combined. To those who are familiar with logistic regression and cross entropy minimisation of softmax, this is a similar approach, but with non-discretised states.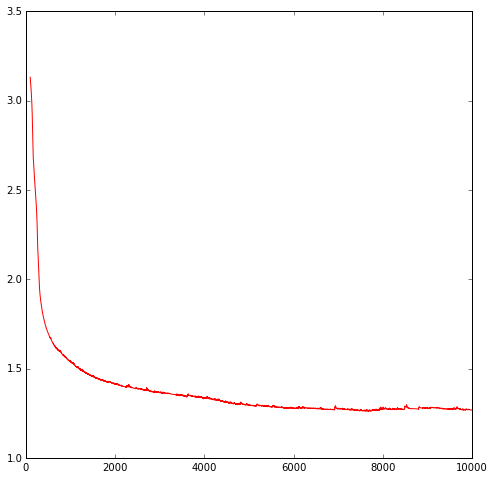
 gaussian distribution.
gaussian distribution.
 as well, and we see what the neural network is sort of doing. For every point on the x-axis, there are multiple lines or states where
as well, and we see what the neural network is sort of doing. For every point on the x-axis, there are multiple lines or states where  may be, and we select these states with probabilities defined by
may be, and we select these states with probabilities defined by 